论文阅读《MemOS: A Memory OS for AI System》
大语言模型正在从一次性问答工具逐渐走向长期运行、持续交互、跨任务协作的 Agent 系统。在这个过程中,一个越来越关键的问题浮现出来:模型如何记住过去?如何更新知识?如何在不同任务、用户和平台之间复用经验?
论文《MemOS: A Memory OS for AI System》正是围绕这个问题展开。它提出,未来的大模型系统不能只依赖模型参数和上下文窗口,也不能把 RAG 当作完整的记忆方案,真正面向长期 Agent 的 AI 系统,需要一个类似操作系统的“记忆操作系统”,把记忆作为一等系统资源进行建模、调度、治理和演化。
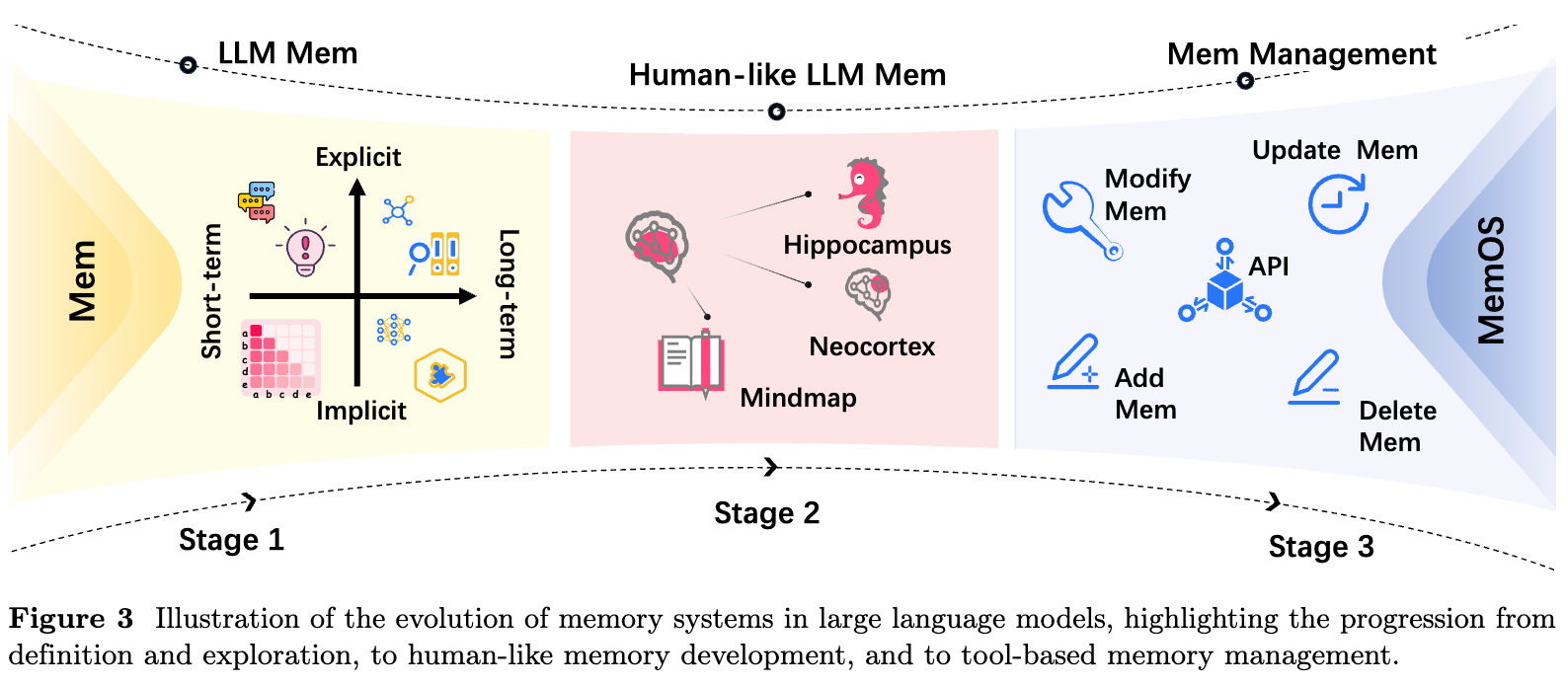
本文主要围绕 MemOS 提出的背景、设计哲学、记忆建模方式,以及整体架构设计对论文进行解读。
MemOS 提出的背景
当前 LLM 的知识主要来自两部分:一部分固化在模型参数中,另一部分来自上下文或外部检索。参数记忆的优势是调用高效,模型可以直接基于权重生成答案,但也有明显问题,即更新成本高、可解释性差、难以局部修改。一旦知识过时,往往需要重新训练、微调或做复杂的模型编辑。RAG 则通过外部检索把文档、知识库、用户资料等内容拼接到上下文中,让模型在生成时参考这些信息。这解决了一部分动态知识接入问题,但论文认为,RAG 本质上仍然是“临时检索 + 上下文拼接”的流程,而不是完整的记忆管理系统。
因为一个真正的记忆系统不仅要能“取出相关内容”,还要回答更多系统性问题,例如:
- 一条记忆什么时候创建、激活、合并、归档、过期?
- 同一个事实更新后,旧版本和新版本如何共存、替换或回滚?
- 某条记忆来自用户输入、模型推理、外部文档,还是参数微调?
- 哪些用户、角色、任务可以访问哪些记忆?
- 用户在一个应用中的记忆,能否迁移到另一个 Agent 或平台?
- 文本记忆、KV Cache、参数模块之间能否互相转换?
这些问题在短会话问答中并不明显,但在长期 Agent 场景中会变得非常关键。这是因为:
- 在 时间维度 上,Agent 需要长期参与用户工作流,记住偏好、历史任务、长期目标和过往决策,并在多轮对话和跨任务过程中保持一致性。
- 在 空间维度 上,模型正在进入多用户、多平台、多角色、多应用的环境。用户可能在 ChatGPT、Cursor、企业知识库和移动端助手之间切换;企业也可能部署多个 Agent 协作完成复杂任务。如果记忆被锁死在单一应用或模型实例中,就会形成“记忆孤岛”。
因此,MemOS 的出发点,是大模型的发展不能只关注“模型本身有多强”,还要关注“模型如何积累经验、组织知识、更新记忆和迁移能力”。
核心思想与记忆建模
MemOS 的核心设计哲学可以概括为一句话,即 将记忆从模型的隐式附属物提升为可建模、可调度、可治理、可演化的系统资源。
过去我们谈大模型能力时,通常默认“知识都在模型参数里”。模型训练完成后,参数就像一个巨大的压缩知识库,里面包含语言规律、世界知识、推理模式和行为偏好。后来 RAG 出现后,大家开始把外部文档也视为一种“记忆”:模型需要什么,就从知识库中检索什么,再塞进上下文。论文认为,这两种理解都还不够完整。真正的大模型记忆不只存在于参数中,也不只存在于外部文档里,它还存在于模型推理过程中的中间状态里,例如 KV Cache、隐藏状态、注意力模式等。
因此,论文将大模型系统中的记忆分为三类:明文记忆、激活记忆和参数记忆。MemOS 的关键不只是区分这三类记忆,而是希望把它们放进同一个系统中统一管理,即什么时候使用明文记忆,什么时候使用激活记忆,什么时候使用参数记忆,什么时候让一种记忆转化为另一种记忆。
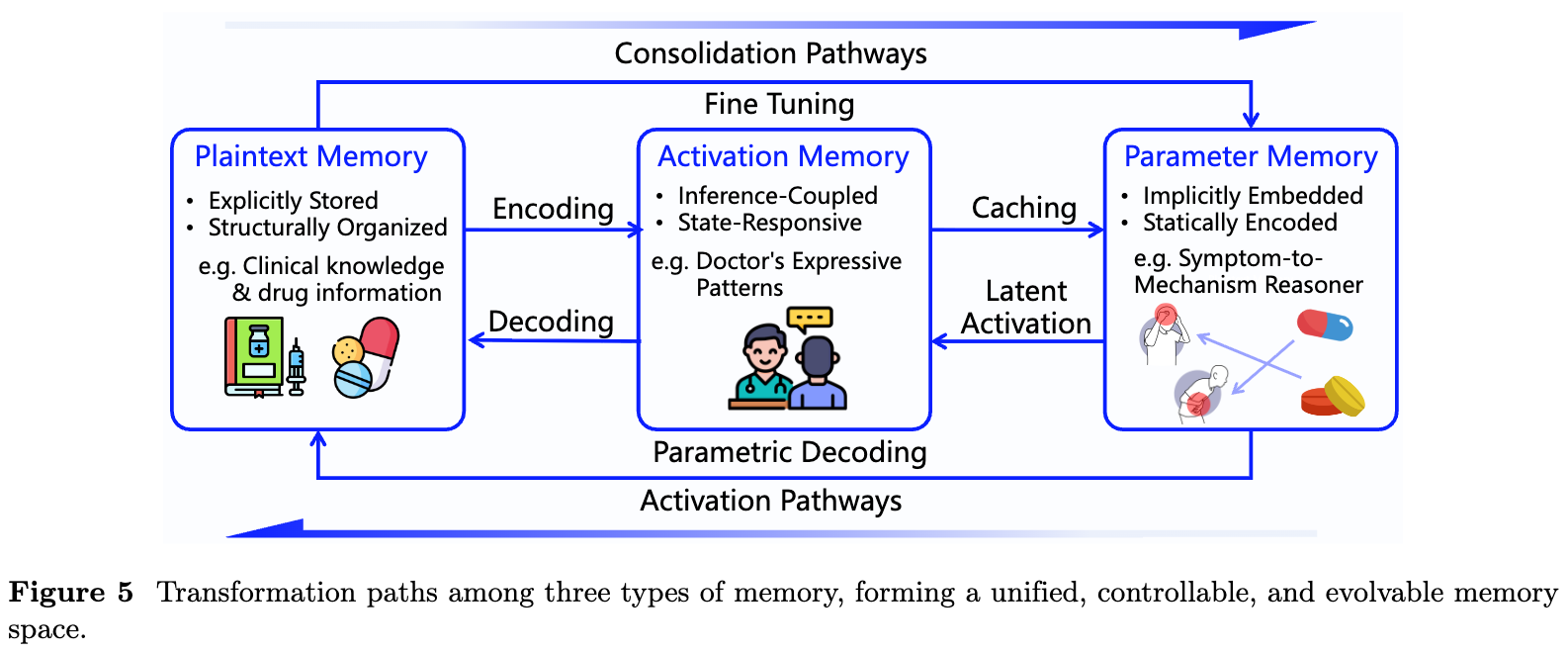
明文记忆:可读、可编辑、可治理的显式知识
明文记忆指的是以自然语言文本、结构化文档、知识图谱节点、Prompt 模板、用户画像、任务记录等形式存在的外部知识。它最接近我们平时理解的“记忆”,也是 RAG 系统中最常见的记忆形态。
例如:
- 用户偏好:“用户喜欢简洁、工程化、带示例的回答风格。”
- 历史事实:“用户上周讨论过 A 项目的预算风险,重点关注供应商交付延迟。”
- 领域知识:“某临床指南在 2025 年更新了某类药物的适应症说明。”
- 工作流规则:“合同审查时优先检查付款条款、违约责任、数据合规和知识产权归属。”
- 对话摘要:“本轮会议确认了三个事项:上线时间、负责人、风险项。”
明文记忆的最大优点是透明,人可以直接阅读它、修改它、删除它,也可以追踪它来自哪里。对于需要审计、解释、纠错和权限管理的场景,明文记忆非常重要。比如一个企业 Agent 记住了“某客户是高优先级客户”,这个信息最好以明文形式保存。因为业务人员可能需要知道:这条记忆是谁写入的?什么时候写入的?依据是什么?现在是否还有效?哪些 Agent 可以使用?如果客户等级变化,是否可以更新或废弃?
这类问题很难只靠模型参数回答,但明文记忆可以通过元数据和权限系统来治理。不过,明文记忆也有如下局限:
- 通常需要检索。系统要先从大量记忆中找到相关内容,再拼接进上下文,这会带来检索延迟和排序误差。
- 消耗上下文窗口。如果每次都把大量历史记录塞进 Prompt,模型的输入会变长,推理成本也会上升。
- 虽然可读性好,但并不天然等于“模型真正理解了”。把一段资料塞进上下文,只是让模型临时看到它,并不代表模型已经把它内化成稳定能力。
所以,明文记忆适合存放那些需要透明、可控、可更新、可追踪的信息,例如用户偏好、企业制度、任务历史、外部知识、动态事实和敏感内容。可以将明文记忆理解为 MemOS 中最“可治理”的记忆层。
激活记忆:推理现场中的短期工作状态
激活记忆指的是模型在推理过程中产生的中间状态,典型代表是 KV Cache,也包括隐藏状态、注意力模式、激活向量等。它不像明文记忆那样可以直接阅读,但它会影响模型接下来如何理解上下文、关注哪些信息、生成什么内容。
如果说明文记忆是写在笔记本里的内容,那么激活记忆更像是“你正在思考时大脑中的工作状态”。例如,当模型读完一段长文后,它不会每生成一个 token 都重新完整阅读前面的所有内容,而是会在注意力机制中复用之前计算出的“键值对”表示。KV Cache 中就保存了这些中间表示,让模型能够更快地继续生成。这在工程上通常被视为推理加速机制,但 MemOS 进一步把它视为一种可管理的记忆。
为什么 KV Cache 也可以被看作记忆?因为它保留了上下文对当前生成过程的影响。即使它不是人类可读文本,也仍然承载了某种“已经处理过的信息”,模型后续生成时会依赖这些状态来保持上下文连贯。例如:
假设一个医疗问诊 Agent 每次与患者对话时都需要参考一段稳定背景信息:
1 | - 患者有糖尿病史。 |
如果每次问诊都把这些信息作为明文 Prompt 拼进去,系统会反复做相同的编码工作。对于高频使用的信息,MemOS 可以将其转化为激活记忆,例如预先编码成 KV Cache,在后续推理时直接加载。这样模型不需要每次重新处理整段文本,进而提高响应速度。
再例如,一个 Code Agent 长期参与某个项目,反复需要记住:
1 | - 项目使用 TypeScript。 |
这些信息最初可能来自明文记忆,但当它们在当前任务中被频繁调用时就可以被调度为激活记忆,让模型在一段工作流中更快、更稳定地保持上下文状态。
激活记忆的优势是低延迟、贴近推理过程、适合短期高频复用,尤其适合多轮对话、长文档处理、代码生成、复杂任务执行等场景。但激活记忆也有如下明显短板:
- 不易解释。KV Cache 或隐藏状态不是自然语言,人很难直接查看其中到底存了什么。
- 通常和具体模型、具体上下文、具体推理过程强绑定,跨模型、跨平台迁移比较困难。
- 适合短期或中期复用,不适合作为唯一的长期知识来源。
激活记忆可以理解为 MemOS 中最“高效”的记忆层,它不一定最透明,但非常适合提升运行时性能和上下文连续性。
参数记忆:内化在模型权重中的长期能力
参数记忆指的是存储在模型权重中的知识和能力。大模型通过预训练、指令微调、RLHF、领域微调、LoRA、Adapter 等方式,把大量语言规律、世界知识、推理模式和行为偏好压缩进参数中,它是最传统意义上的“模型知识”。例如,一个基础模型能够回答“中国的首都是北京”、能够理解中文语法、能够写 Python 代码、能够总结文章、能够进行基本数学推理,这些能力主要来自参数记忆。
参数记忆和明文记忆最大的区别是:它不是被显式检索出来的,而是在模型生成时自然参与计算。模型不需要从外部数据库中取出“如何写 Python 函数”的文档,很多能力已经内化在权重里了。参数记忆的优势非常明显,典型的包括:
- 调用成本低。只要模型加载完成,参数记忆就天然参与推理,不需要额外检索。
- 泛化能力强。参数中存储的不是一条条孤立文本,而是经过训练形成的模式和能力。
- 适合稳定知识和通用能力。例如语言能力、通用推理能力、常识、长期稳定的专业技能等。
但它的问题也同样明显,包括:
- 更新成本高。如果某个知识过时,不能像改文档一样简单修改参数。
- 可解释性弱。我们很难准确指出某条知识存储在哪些参数中。
- 局部修改风险大。模型编辑或微调可能修正一个事实,但也可能影响其他能力,甚至造成灾难性遗忘。
- 不适合频繁变化的个性化信息。比如“用户今天改了饮食偏好”这种信息,显然不应该立刻写进模型参数。
因此,MemOS 并不主张所有记忆都进入参数,而是把参数记忆视为一种适合承载长期稳定能力的记忆层。例如:
- 一个法律 Agent 长期需要掌握合同审查方法,可以通过参数模块内化“合同审查能力”。
- 一个金融 Agent 长期需要识别财报风险,可以通过 LoRA 或 Adapter 学到稳定分析模式。
- 一个写作 Agent 长期需要某种文风,可以把稳定风格蒸馏成参数化能力。
- 一个企业内部 Agent 可以把高频且稳定的流程规则转化为轻量参数模块,而不是每次都检索文档。
在 MemOS 的视角下,参数记忆不是不可触碰的黑盒,而是一种可以被加载、卸载、蒸馏、补丁化和治理的长期记忆资源。可以把参数记忆理解为 MemOS 中最“内化”的记忆层。
三类记忆的差异与演化
这三类记忆并不是互相替代关系,而是对应不同的使用场景:
- 明文记忆适合“需要看得见、改得动、能审计”的信息。比如用户偏好、企业知识、最新政策、任务记录、敏感资料等。
- 激活记忆适合“当前任务中高频使用、需要快速响应”的信息。比如长对话状态、当前项目上下文、固定角色设定、反复调用的背景材料等。
- 参数记忆适合“长期稳定、可泛化、需要内化为能力”的信息。比如语言能力、专业技能、稳定工作流、长期风格偏好、可复用推理模式等。
可以用一个具体例子来串起来,假设我们有一个长期陪伴医生工作的医疗 Agent,一开始医院上传了一批临床指南和药品说明书,这些内容以明文记忆形式进入系统。它们可读、可检索、可追踪来源,也可以随着指南更新进行版本管理。当某位医生今天连续接诊同一类患者时,系统发现某些诊疗流程、患者背景和注意事项被频繁调用,于是将相关内容转化为激活记忆,以 KV Cache 形式加速后续问答,减少重复编码。经过长期使用后,系统发现某些问诊策略、病历总结格式、风险提醒模板非常稳定,并且在大量任务中反复出现,就可以把这些模式蒸馏进参数模块,形成某种“临床问诊助手能力”。
这样,同一份知识可能经历这样的路径:
1 | 明文记忆:临床指南、患者历史、医生备注 |
反过来,如果某个参数化能力过时,MemOS 也可以通过明文记忆进行补丁修正。例如旧参数中学到的指南已经过期,系统可以优先调度新版本明文记忆,并逐步降低旧参数知识的影响。这就是 MemOS 强调“记忆可演化”的原因。
如果只使用明文记忆,系统会变得透明但低效,容易受到上下文长度和检索质量限制。如果只依赖激活记忆,系统会很快但难以解释,也不适合长期归档和跨平台迁移。如果只依赖参数记忆,系统会高效且泛化强,但难以更新、难以治理,也不适合保存个性化和时效性信息。
因此,MemOS 的设计重点不是选择其中一种,而是让系统根据任务自动判断:当前最适合使用哪种记忆,是否需要组合使用,是否需要在不同记忆形态之间迁移。例如:
- 对于“用户今天的偏好变更”,优先写入明文记忆。
- 对于“当前长对话中反复使用的背景”,可以提升为激活记忆。
- 对于“长期稳定的专业流程”,可以沉淀为参数记忆。
- 对于“过时但仍需保留审计记录的信息”,可以从活跃记忆降级为归档明文记忆。
- 对于“频繁被调用的用户规则”,可以先从明文进入激活层,再在足够稳定后变成参数模块。
这正是 MemOS 相比普通 RAG 更进一步的地方。普通 RAG 主要解决“检索什么文本”,而 MemOS 试图解决“记忆作为资源应该如何组织、调度、更新、迁移和演化”。从这个角度看,MemOS 的目标不是给大模型外挂一个知识库,而是为大模型建立一套记忆操作系统,让记忆像计算资源一样被管理,让 Agent 能够在长期交互中积累经验、保持状态,并持续进化。
MemOS 系统架构设计
如果说三类记忆回答了“MemOS 管理什么”的问题,那么 MemCube 和三层架构设计则回答的是“MemOS 如何管理”的问题。
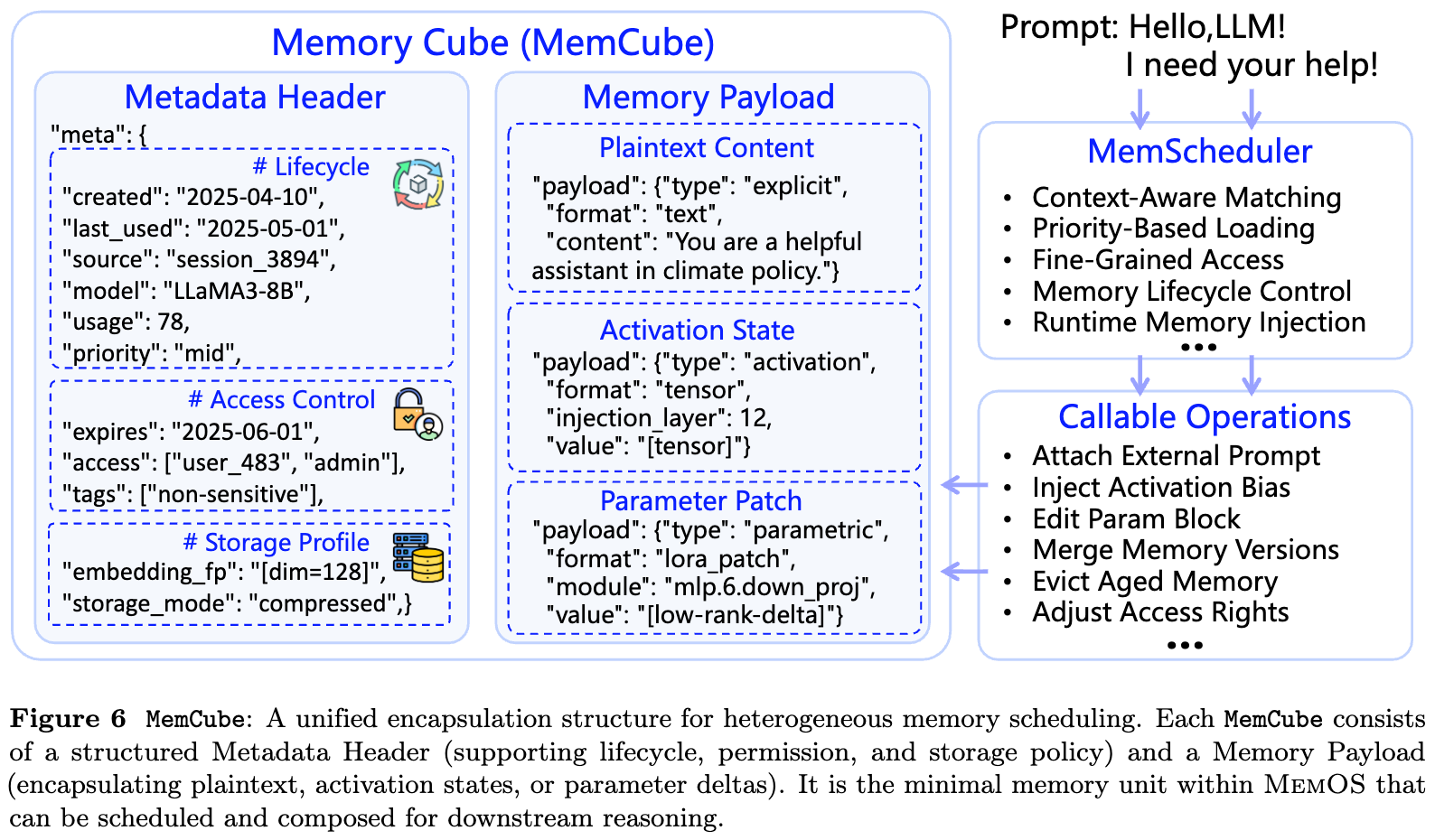
为了统一管理异构记忆,MemOS 引入了 MemCube 的设计,它是系统中最小的可调度记忆单元。一个 MemCube 由两部分组成:Memory Payload 和 Metadata,前者是记忆内容本身,可以是明文文本、激活张量、KV Cache、参数补丁、LoRA 模块等,而后者则描述这条记忆的身份、治理规则和行为指标。
论文将 Metadata 大致分成三类:
- 描述性标识,用来回答“这条记忆是谁、从哪里来、属于什么类型”。例如创建时间、更新时间、来源签名、模型标识、语义类型、标签等。
- 治理属性,用来回答“谁可以访问、能用多久、是否敏感、如何审计”。例如访问控制列表、TTL、优先级、敏感标签、水印、合规日志等。
- 行为使用指标,用来回答“这条记忆是否重要、是否高频、是否应该迁移”。例如访问频率、最近使用时间、上下文指纹、版本链、冷热状态等。
MemCube 的意义在于,它把不同形态的记忆统一成了系统可以理解和操作的资源。无论一条记忆是文本、KV Cache,还是参数补丁,只要被封装为 MemCube,就可以被调度、组合、迁移、归档和审计。这也是 MemOS 区别于普通 RAG 系统的关键。普通 RAG 管理的是文档片段,而 MemOS 管理的是带有生命周期、权限、版本、行为指标和演化路径的记忆单元。
围绕 MemCube,论文提出 MemOS 采用三层架构:接口层、操作层和基础设施层。三层共同完成从用户输入到记忆调用、状态更新、存储归档和权限治理的完整闭环。
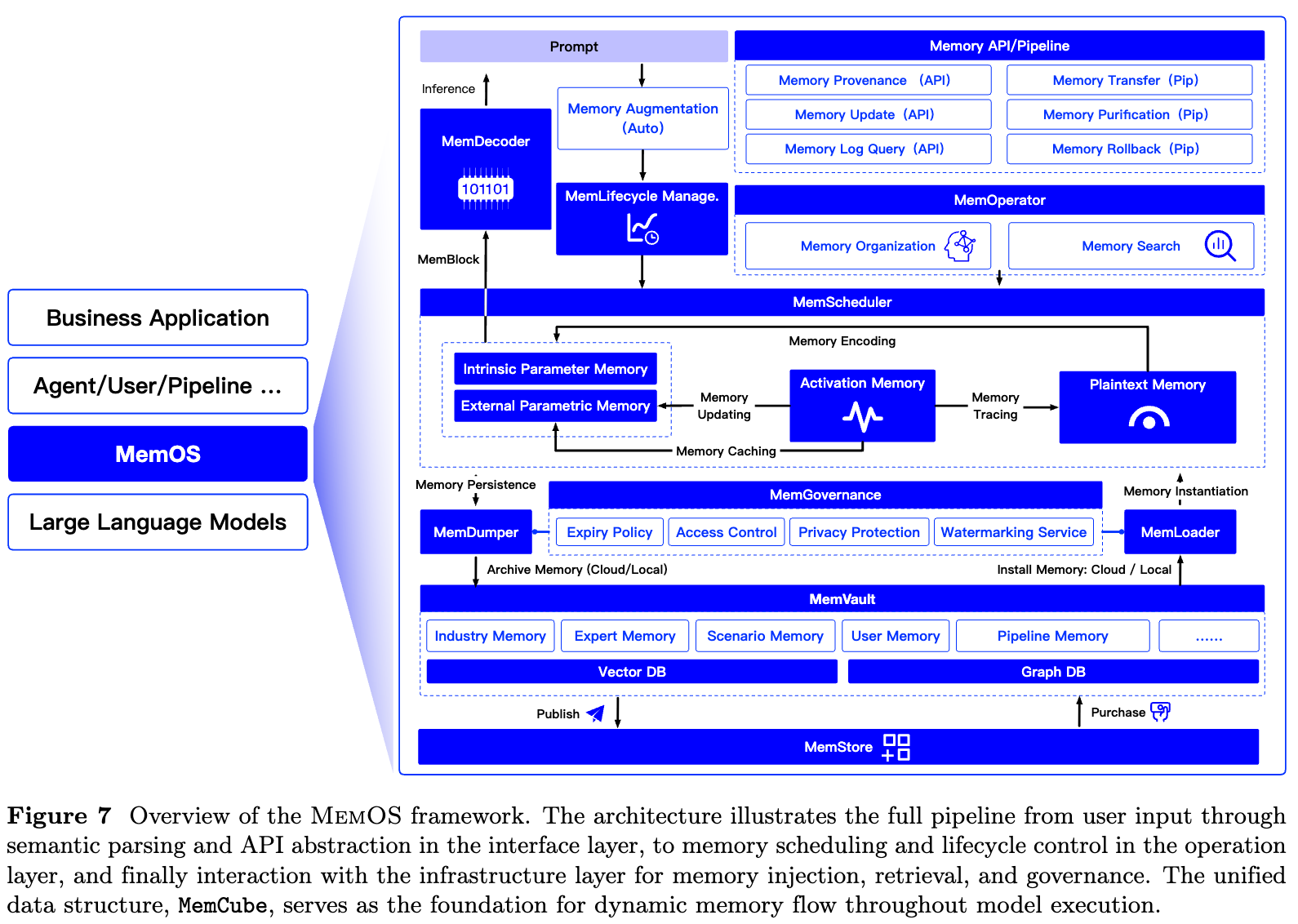
接口层:把自然语言请求转成记忆操作
接口层是用户、业务系统或 Agent 与 MemOS 交互的入口,主要包括 MemReader、Memory API 和 Memory Pipeline。
MemReader 负责理解用户输入中的记忆意图,它会从自然语言中解析任务意图、时间范围、实体对象、上下文锚点和记忆类型。例如用户说:“帮我总结一下上个月的会议纪要。” MemReader 需要识别出:
1 | - 操作意图是查询和总结。 |
随后,MemReader 会把这些信息封装成结构化的 MemoryCall 交给下游模块处理。
Memory API 则提供标准化操作接口,例如创建、查询、更新、回滚、溯源、日志查询等。所有 API 调用都以 MemCube 作为输入或输出载体,并受到权限和审计机制约束。
Memory Pipeline 用于复杂任务编排。比如一个医疗助手可以定义“检索历史用药记录、加入医生最新建议、更新来源信息、归档本次问诊摘要”的流水线。流水线可以支持事务一致性、回滚和错误隔离,让记忆操作不再是零散调用,而是可组合的任务流程。
操作层:记忆调度和组织的控制中心
操作层是 MemOS 的核心,主要包括 MemOperator、MemScheduler 和 MemLifecycle。
MemOperator 负责组织和检索记忆,结合标签系统、知识图谱和语义分层,把记忆组织成可导航结构。它既支持基于标签、时间范围、权限条件的结构化检索,也支持基于向量相似度的语义检索。例如在企业问答场景中,用户问“上季度 A 项目的预算风险是什么”,MemOperator 可以根据项目标签、时间范围、财务主题和用户权限,定位相关记忆,再通过语义排序选出最合适的片段。
MemScheduler 是 MemOS 中最关键的调度器,不只是决定“检索哪条记忆”,还要决定“以什么形态调用记忆”。对于需要快速响应的高频内容,它可能选择激活记忆;对于稳定的专业能力,它可能选择参数模块;对于时效性强或个性化内容,它可能选择明文记忆。这种调度会考虑任务语义、上下文窗口大小、访问频率、资源约束、缓存命中率、优先级和权限策略,体现了 MemOS 的系统属性,即记忆调用不是简单 TopK 检索,而是资源调度问题。
MemLifecycle 负责记忆状态管理。论文中提到的主要状态包括 Generated、Activated、Merged、Archived,也在执行流程中提到 Expired。直观理解如下:
1 | - Generated:新生成或新写入的记忆。 |
MemLifecycle 还提供类似“时间机器”的机制,支持快照和回滚,这对于用户撤回、合规审计、版本比较、反事实分析都很重要。
基础设施层:存储、治理、迁移和共享
基础设施层为 MemOS 提供持久化存储、安全治理和跨平台流动能力,主要包括 MemGovernance、MemVault、MemLoader、MemDumper 和 MemStore。
MemGovernance 负责权限控制、隐私保护、审计和合规。它建立了用户身份、记忆对象和调用上下文之间的三元权限模型,每次记忆调用都需要根据用户角色、任务上下文和记忆权限进行验证。例如在医疗场景中,医生可以查看完整诊断记录,患者可能只能查看脱敏摘要,研究机构只能访问去标识化数据。MemGovernance 还负责敏感信息检测、自动脱敏、水印、访问日志和来源追踪。
MemVault 是核心存储和路由组件,它管理用户私有记忆、专家知识库、行业共享记忆、上下文记忆池、流水线缓存等不同命名空间。底层可以接入向量数据库、关系型数据库、图数据库和对象存储,并通过统一适配器屏蔽后端差异。
MemLoader 和 MemDumper 负责记忆导入和导出,它们让 MemCube 可以在本地、云端、第三方系统和不同 Agent 之间迁移。导出时需要携带权限、来源、脱敏字段和访问日志,导入时需要补充元数据和生命周期状态。
MemStore 则更像一个记忆市场或记忆分发平台。专家、机构或用户可以发布可共享的记忆单元,其他 Agent 可以按权限订阅、安装和调用。论文甚至提出了“Paid Memory as Modular Installables”的想法,即专家经验可以像插件一样被发布、购买和安装。
一次记忆调用的执行过程
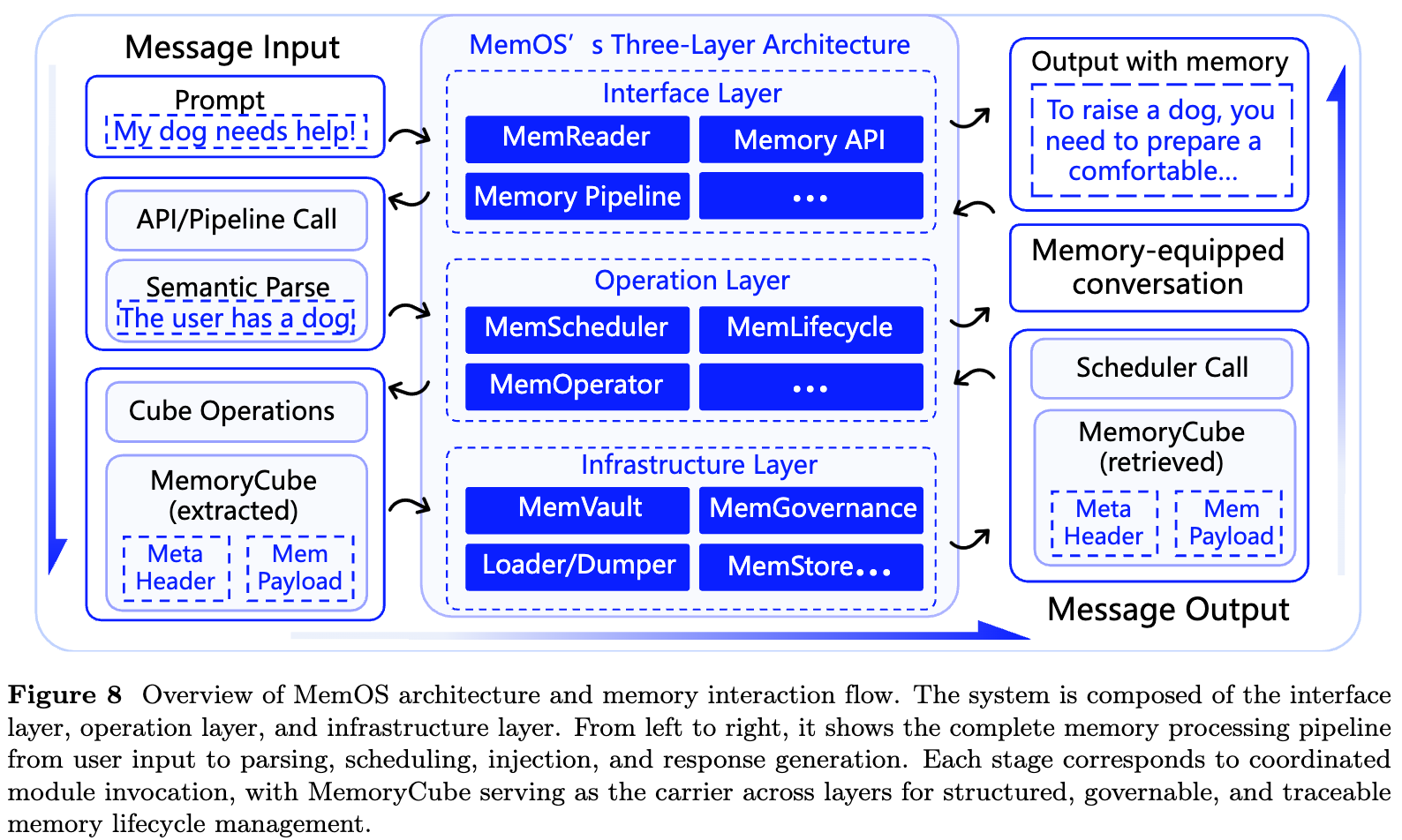
综合 MemCube 和三层架构,MemOS 的一次典型执行流程大致如下:
- 用户输入自然语言请求后,MemReader 首先解析其中的记忆意图、时间范围、实体和上下文锚点。如果请求需要访问记忆,系统会生成结构化 MemoryCall,并通过 Memory API 传递给操作层。
- MemOperator 根据 MemoryCall 构建检索路径,结合标签、图关系、语义向量和权限约束找到候选记忆。
- MemScheduler 对候选记忆进行调度,决定哪些记忆需要被激活,以什么顺序、什么形态注入模型,期间可能同时使用明文记忆、激活记忆和参数记忆。
- MemLifecycle 更新这些记忆的状态,被频繁调用的记忆可能从 Generated 变为 Activated;语义重复的记忆可能被合并;长期未访问的记忆可能被归档;过期记忆可能被清理。
- MemVault 负责存储和归档,MemGovernance 负责权限、审计和合规,必要时通过 MemStore 或 Loader/Dumper 完成共享和迁移。
这个流程使记忆从“被动存储的信息”变成“在任务执行中不断流动和演化的资源”。
总结
这篇论文的核心可以总结为:大模型要成为长期 Agent,必须拥有系统级记忆管理能力,而记忆管理不能停留在 RAG 或历史对话缓存层面,应像操作系统管理计算资源一样,管理不同类型、不同生命周期、不同权限范围的记忆资源。在系统设计层面,MemOS 引入 MemCube 统一记忆单元,通过建立三类记忆模型打通了明文记忆、激活记忆和参数记忆之间的边界,设计三层架构则把记忆解析、调度、生命周期、存储、治理和迁移组织成完整系统。
如果说预训练让模型拥有“知识”,后训练让模型更会“遵循指令”,那么 MemOS 代表的方向是让模型开始拥有“经验管理能力”。这可能是大模型从工具走向长期 Agent 路上必须补上的一层基础设施。