通过图片分类任务探寻 Daft 运行机制之 Flotilla 引擎篇
在 DATA + AI 数据科学领域,Pandas 无疑是数据科学家和开发者们的“瑞士军刀”。凭借相对完善的 DataFrame API 和丰富的生态,Pandas 极大简化了在中小型数据集上的数据清洗、分析和探索性工作。然而,随着数据集规模的增长,Pandas 在执行效率和资源开销层面的短板也逐渐凸显,因此诞生了 Polars、Dask 一类的产品:
Polars 采取纵向优化策略,通过 Rust 语言对引擎内核进行重新设计和实现,并引入查询优化器、向量化执行引擎等手段以进一步提升执行性能,但开源版本仅提供单机运行模式。
Dask 则采用横向优化策略,可以将其看作是 Pandas 的分布式实现。
Daft 则融合了 Polars 和 Dask 二者的优势,在内核层面采用 Rust 语言实现,并提供 Python DataFrame 和 SQL 接入 API,同时提供单机和分布式两套执行引擎,并支持无缝切换运行模式。重要的是,Daft 内置多模态类型和算子,并依托于 Ray 实现异构资源管理,从而将应用领域由传统结构化数据处理拓展至多模态数据处理场景。
此前,我们曾在文章《通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇》中通过一个典型图片分类任务,由浅入深介绍了 Daft 单机执行引擎 Swordfish 的运行机制。本文我们将沿用这个示例,继续探寻 Daft 分布式执行引擎 Flotilla 的设计与实现。
本文英文版本已发布至 Daft 官网:“Distributed Model Inference with Daft: A deep dive into Daft’s distributed execution engine, Flotilla, for multimodal data pipelines”
一键切换至分布式模式运行
我们再来回顾一下这个图片分类任务示例程序,不过这次稍微对其做了一些修改,增加了 into_batches 逻辑,具体如下所示。通过 into_batches 将数据切分成合适大小的批次,对于包含需要基于 URL 实时下载数据的场景来说是一个不错的优化项,因为这样能够将下载任务分发给更多的节点执行,以尽量发挥分布式执行的优势,避免单节点网络资源成为瓶颈。
1 | df = (daft |
Daft 默认以单机模式执行上述程序,如果你希望切换至分布式模式执行以支撑更高的负载,则只需少量配置或修改即可实现。Daft 分布式执行引擎底层依赖 Ray 做资源管理,因此最简单的方式是通过 export DAFT_RUNNER=ray 设置环境变量进行切换,或者在代码中显式指定使用 Ray Runner:
1 | daft.set_runner_ray(address="ray://...") |
更多关于 Daft on Ray 分布式运行的介绍可以参考 官方文档。
Flotilla 分布式引擎整体架构
Flotilla 分布式执行引擎在整体架构设计上可以简单理解为 Swordfish 单机执行引擎的分布式版本,通过统筹协调多个 Swordfish 单机引擎进行组建。在实现层面,Flotilla 依赖 Ray 做异构资源管理,并在每个 Ray Worker 节点上启动一个名为 RaySwordfishActor 的常驻 Ray Actor,用于接收和执行单机版的物理执行计划。当用户提交一个 Query 请求时,Flotilla 会首先将 Query 对应的分布式物理执行计划拆分成一系列可被 Swordfish 单机引擎执行的 SwordfishTask,然后通过内置的调度器将这些 SwordfishTask 调度分发给对应的 RaySwordfishActor 节点,而每个 RaySwordfishActor 在内部会运行一个 Swordfish 单机执行引擎,以此实现执行调度给当前 RaySwordfishActor 节点的执行计划。
如上图所示展示了构成 Flotilla 分布式执行引擎的核心组件:
RayRunner: 类比 Swordfish 单机执行引擎中的 NativeRunner,Flotilla 引擎依托 Ray 做异构资源管理,因此提供了 RayRunner 组件负责在本地启动 Ray 集群实例或与指定远端 Ray 集群建连。此外,RayRunner 还负责通过 FlotillaRunner 向 Ray 集群提交 Query 对应的逻辑执行计划,并输出执行结果。
FlotillaRunner: 可以理解为 Flotilla 引擎与运行在 Ray 集群上组件进行交互的客户端实现,负责在 Ray 集群 Head 节点上启动 RemoteFlotillaRunner,并提交执行 Query 对应的逻辑执行计划,同时轮询读取执行结果。
RemoteFlotillaRunner: Flotilla 引擎运行在 Ray 集群上的 API Server 实现,负责接收客户端提交的 Query 对应的逻辑执行计划,并返回执行结果给到客户端。
DistributedPhysicalPlanRunner: 可以理解为 Flotilla 引擎的服务端实现,DistributedPhysicalPlanRunner 本身只是 Python 和 Rust 交互的胶水层,核心实现是 PlanRunner。PlanRunner 负责将优化后的逻辑执行计划转换成分布式物理执行计划,并进一步生成一系列可被调度执行的 SwordfishTask,通过调度器 Scheduler 和分发器 Dispatcher 将 SwordfishTask 调度分发给运行在 Ray 集群上的各个 RaySwordfishActor 执行。
Flotilla 引擎服务端主要采用 Rust 语言编写,除了 PlanRunner,还包含 RayWorkerManager、Scheduler、Dispatcher 和 RaySwordfishActor 几个核心组件:
RayWorkerManager: 负责与 Ray 集群进行交互,提供了一系列与 Ray 集群进行交互的接口,包括感知 Ray 集群 Worker 节点列表、在 Worker 节点上启动运行 RaySwordfishActor、向目标 Worker 节点批量提交 SwordfishTask,以及集群扩容等。
Scheduler: Flotilla 引擎的调度器实现,负责按照任务具体的调度策略为每个待调度的 SwordfishTask 规划 Worker 节点。Scheduler 在内部通过一个优先级队列维护由 PlanRunner 提交待调度的 SwordfishTask 集合,并通过一个事件循环轮询消费该队列、更新本地记录的 Ray Worker 节点状态,以及按需触发对集群进行扩容。
Dispatcher: Flotilla 引擎的分发器实现,负责将 SwordfishTask 按照目标 Worker ID 进行分组,并依托 RayWorkerManager 批量提交给指定的 Worker 节点执行。Dispatcher 会在 Scheduler 的事件循环中被周期性触发调用。
RaySwordfishActor: 负责执行由 Dispatcher 提交给所在 Worker 节点上的 SwordfishTask。RaySwordfishActor 可以看作是一个常驻的 Swordfish 单机执行引擎,内部通过 NativeExecutor 执行接收到的 SwordfishTask。
介绍完了 Flotilla 引擎的整体架构,我们再来简单聊聊 Flotilla 诞生的背景。Flotilla 可以看做是 Daft 分布式执行引擎的 v2.0 版本(或者叫 v1.5 版本更加确切),也是当前版本默认启用的分布式引擎,而 v1.0 版本(即 Legacy Ray Runner)已经在最新版本中被移除。之所以要重新设计分布式执行引擎,主要是考虑 Legacy Ray Runner 在实现层面会将整个执行层都交由 Ray 来负责,Daft 能够做的仅仅是执行计划的规划、任务拆分和提交。这导致 Daft 对于任务的实际调度和执行可操作性很受限,存在 2 个核心问题:
执行性能低: 对于稍复杂的作业通常会切分成多个 Stage,每个 Stage 包含大量的任务,Daft 在将这些任务提交后,Ray 集群会按照提交顺序对任务进行调度执行。当任务数较多时往往会导致执行模式由 Pipeline 退化成 Stage by Stage。对于多模态数据处理这类异构计算场景,极易造成资源得不到充分利用,进而导致处理性能低效。
内存压力大: Ray 集群通过 Object Memory Store 实现任务之间的数据交换,而 Stage by Stage 的执行模式需要将上游 Stage 全部处理完成之后再开始执行下游 Stage,中间的处理结果需要全部由 Object Memory Store 承载,这给 Ray 集群造成了极大的内存压力,极易导致 OOM 错误。
Flotilla 相对于 Legacy Ray Runner 的核心改变是将任务的调度层和执行层从 Ray 层面剥离,改为由自己完全掌控,Ray 则简化成仅仅充当异构资源管理角色。 在调度层面,Flotilla 内置的 Scheduler 能够保证 Pipeline 中的各个节点均能获得运行所需的资源,让数据能够在 Pipeline 中流式被处理,不至于造成 Pipeline 堵塞。在执行层面,Flotilla 能够复用单机执行引擎 Swordfish 优秀特性,包括 Pipeline 架构、动态数据分片,以及向量化执行等。
Flotilla 分布式引擎运行机制
在了解了 Flotilla 分布式引擎的整体架构之后,本小节继续回到图片分类示例程序,从引擎内部视角探寻 Flotilla 的运行机制。
如上图展示了 Flotilla 内部运行时的整体执行时序:
- RayRunner 和 FlotillaRunner 可以理解为 Flotilla 分布式引擎的客户端实现,其中 RayRunner 对应 Swordfish 单机引擎中的 NativeRunner。
- RemoteFlotillaRunner 可以理解为 Flotilla 分布式引擎的 API 接口层,运行在 Ray 集群的 Head 节点上。客户端 FlotillaRunner 通过调用其
run_plan和get_next_partition等 remote 方法实现提交 Query 对应的执行计划,并获取各个执行完成的分区计算结果。 - PlanRunner 可以理解为 Flotilla 分布式引擎的服务端实现,采用 Rust 语言编写,通过 DistributedPhysicalPlanRunner 实现与 Python 侧 RemoteFlotillaRunner 的交互,并在内部定义了 RayWorkerManager、Scheduler 和 Dispatcher 等组件共同完成对于执行计划的处理。
- PlanRunner 在内部定义了一个 Result Channel 用于收集计算完成的分区数据;DistributedPhysicalPlanRunner 通过将该 Channel 包装成为一个迭代器返回给 Python 侧的 RemoteFlotillaRunner;客户端 FlotillaRunner 通过循环调用
get_next_partition方法以触发 RemoteFlotillaRunner 遍历该迭代器返回执行完成的分区结算结果。
基于物理执行计划生成可执行任务
我们在《通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇》一文中介绍了 Daft 如何将示例程序对应的 DataFrame 在引擎内部转换并优化得到逻辑执行计划。逻辑执行计划本质上是引擎在内部对用户构建的 DataFrame 在逻辑语义层面的表示,并不能直接被调度执行,还需要进一步将其转换成物理执行计划,并最终封装成可调度执行的任务列表。
1 | * Sink: DataSink(Lance Write) |
引擎在基于逻辑执行计划构造物理执行计划时需要关注具体在什么平台上执行,是单机执行还是分布式执行等问题。上述展示了示例程序使用分布式执行引擎 Flotilla 执行时对应的物理执行计划,感兴趣的读者可以将其与《通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇》一文中展示的单机执行引擎 Swordfish 对应的物理执行计划相比对,还是有些细微的差别。不过,同单机物理执行计划一样,构造分布式物理执行计划的过程同样可以简单理解为是对逻辑执行计划树进行深度优先遍历,并一一映射算子的过程,即将逻辑算子映射成为物理算子。
物理执行计划本质上是一棵静态树结构,所以并不能将其直接丢给引擎去执行,因此接下来需要将上述物理执行计划拆分成一系列可调度执行的任务。例如上述物理执行计划会被拆分成如下图所示的两个 Stage( 说明:这里的 Stage 并非 Flotilla 的原生概念,而是用来表示一类 SwordfishTask,或者使用 Fragment 命名会更好? ),每个 Stage 包含一个由多个算子节点构成的 Pipeline 管道:
在实现层面,Flotilla 会对物理执行计划树进行深度优先遍历,并应用各个节点的 produce_tasks 方法生成对应的 SwordfishTask 集合。以上述物理执行计划为例,我们挑选几个具有代表性的节点展开介绍:
ScanSourceNode 节点: 对于 Scan 节点而言,我们曾在《通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇》中介绍过,物化 Scan 算子的优化规则会基于数据源按规则切分构造一系列 ScanTask。Flotilla 在这一步会通过单机 PhysicalScan 节点逐一封装各个 ScanTask 并生成对应的 SwordfishTask 任务列表。
IntoBatches 节点: IntoBatches 节点用于将分区数据按照指定的
batch_size进行切分或合并,因此会涉及到对数据的重分片,进而影响 SwordfishTask 执行的并行度,因此可以看到 IntoBatches 会将执行计划拆分成两个 Stage。在实现层面,IntoBatches 分为 Local 和 Global 两阶段来实现,即如果分区中包含的数据条数大于batch_size设置的值,则会先在 Scan 节点节点侧进行局部切分,在局部切分不满足batch_size约束的情况下会进一步在数据接收侧进行进一步攒批,从而尽量保证向后投递的数据条数满足batch_size约束。此外,需要澄清的一点是,IntoBatches 虽然将执行计划切分成了两个 Stage,但两个 Stage 中对应的 SwordfishTask 仍然采用流式模式执行。 Flotilla 并不会阻塞等待 Stage 0 中的所有 SwordfishTask 执行完成后才开始调度 Stage 1 中的 SwordfishTask,而是当数据条数满足batch_size约束后即动态生成并调度 Stage 1 中的 SwordfishTask,从而提升整体执行效率和资源利用率。ActorUDF 节点: 对于指定了
concurrency参数的 UDF 会被转化成 ActorUDF 节点,在生成对应的 SwordfishTask 期间,Flotilla 会按照concurrency参数设置启动对应数量的 Ray UDFActor 实例以运行用户编写的 UDF 逻辑,并在启动期间执行 UDF 的初始化逻辑。此外,Flotilla 会将 ActorUDF 节点包装成对应的 DistributedActorPoolProject 节点与上游物理执行计划一起构成新的物理执行计划并生成对应的 SwordfishTask。
总体而言, 生成 SwordfishTask 的过程核心是将一个大的分布式物理执行计划按 Stage 切分成多个小的单机物理执行计划片段的过程。 除了需要触发切分 Stage 的算子外(例如上述介绍的 IntoBatches),Flotilla 会尽量将分布式物理执行计划中的各个节点一一映射成对应的单机物理执行计划节点,并将这些节点串起来构造成为一个完整的单机物理执行计划,而每个单机物理执行计划需要生成多少 SwordfishTask 实例通常由源头节点的并行度所决定。
此外,本示例中由 IntoBatches 切分出来的两个 Stage 虽然能够采用流式模式执行,但 Flotilla 并不是针对所有切分出来的 Stage 都能做到流式,具体还是要视具体触发 Stage 切分的算子而定。例如,以 Broadcast Join 节点为例,因为需要将小表的数据广播到各个数据接收节点,因此这里就需要阻塞等待加载小表的全量数据。在实现层面,Flotilla 会先阻塞执行前置 Stage 节点的 PhysicalScan 任务,当完成对于广播表数据的加载后,Flotilla 会将这部分数据包装成 InMemoryScan 节点,同时遍历接收侧的各个 SwordfishTask 对应的 PhysicalScan 节点,并为每个 PhysicalScan 节点绑定一个 InMemoryScan 节点,以此实现广播的语义,最后通过对 PhysicalScan 和 InMemoryScan 节点附加 HashJoin 算子以进一步实现 Join 语义。
统筹并管理 Ray 集群 Worker 节点
在将物理执行计划拆分成一系列 SwordfishTask 之后,Flotilla 需要将其调度分发给 Ray 集群执行,但在具体深入分析之前,我们先来了解一下 Flotilla 是如何管理 Ray 集群的。
Flotilla 对于物理执行计划的规划、任务调度分发,以及运行状态管理等均在 Ray 集群的 Head 节点上完成,而对于任务的具体执行则由 Ray 集群的各个 Worker 节点承载。Flotilla 在内部定义了 WorkerManager 角色用于抽象对于分布式集群的管理和交互,核心功能包括集群节点感知与管理、任务提交与状态维护,以及弹性伸缩等,并针对 Ray 集群提供了 RayWorkerManager 实现。
- 集群状态感知
RayWorkerManager 实现了 WorkerManager#worker_snapshots 方法用于感知并记录所在 Ray 集群的 Worker 节点列表和资源信息(包括 CPU、GPU 和内存)。Flotilla 调度器会周期性调度该方法以保证本地记录的集群状态信息的新鲜度。对于感知到的每个 Ray Worker 节点,Flotilla 会在上面启动运行一个名为 RaySwordfishActor 的 Ray Actor 实例。 RaySwordfishActor 在内部运行着一个 Swordfish 单机执行引擎,负责以单机模式执行由 Scheduler 调度分发过来的单机物理执行计划。
- 任务提交运行
RayWorkerManager 实现了 WorkerManager#submit_tasks_to_workers 方法用于向指定 Worker 节点批量提交执行任务。这些任务会被封装成 SwordfishTask 实例(定义如下),核心是定义了可以被 Swordfish 单机引擎执行的物理执行计划,以及对应需要处理的数据分区元信息:
1 | pub(crate) struct SwordfishTask { |
我们知道 Flotilla 会在每个 Worker 节点上启动运行一个 RaySwordfishActor,而这里的 SwordfishTask 最终会被发送给对应 Worker 节点上的 RaySwordfishActor 进行处理。RaySwordfishActor 定义了 RaySwordfishActor#run_plan 异步方法,该方法在内部会创建 NativeExecutor,并调用 NativeExecutor#run 方法通过 Swordfish 单机引擎执行接收到的物理执行计划和分区数据。关于 NativeExecutor 的运行机制,我们曾在《通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇》一文中深入分析并介绍过,不了解的读者可以参阅该文章,这里不再重复撰述。
SwordfishTask 任务调度与分发执行
对于前面由物理执行计划生成得到的一系列 SwordfishTask,Flotilla 会将其提交给调度器 Scheduler 调度执行,并获取各个任务的执行结果,整体执行时序如下图所示。在了解了 Flotilla 如何管理 Ray 集群 Worker 节点,以及 Worker 如何执行 Flotilla 调度分发的 SwordfishTask 之后,我们继续来看 Flotilla 如何将这些 SwordfishTask 规划、调度分发给 Worker 节点,并对任务执行状态实施管理。
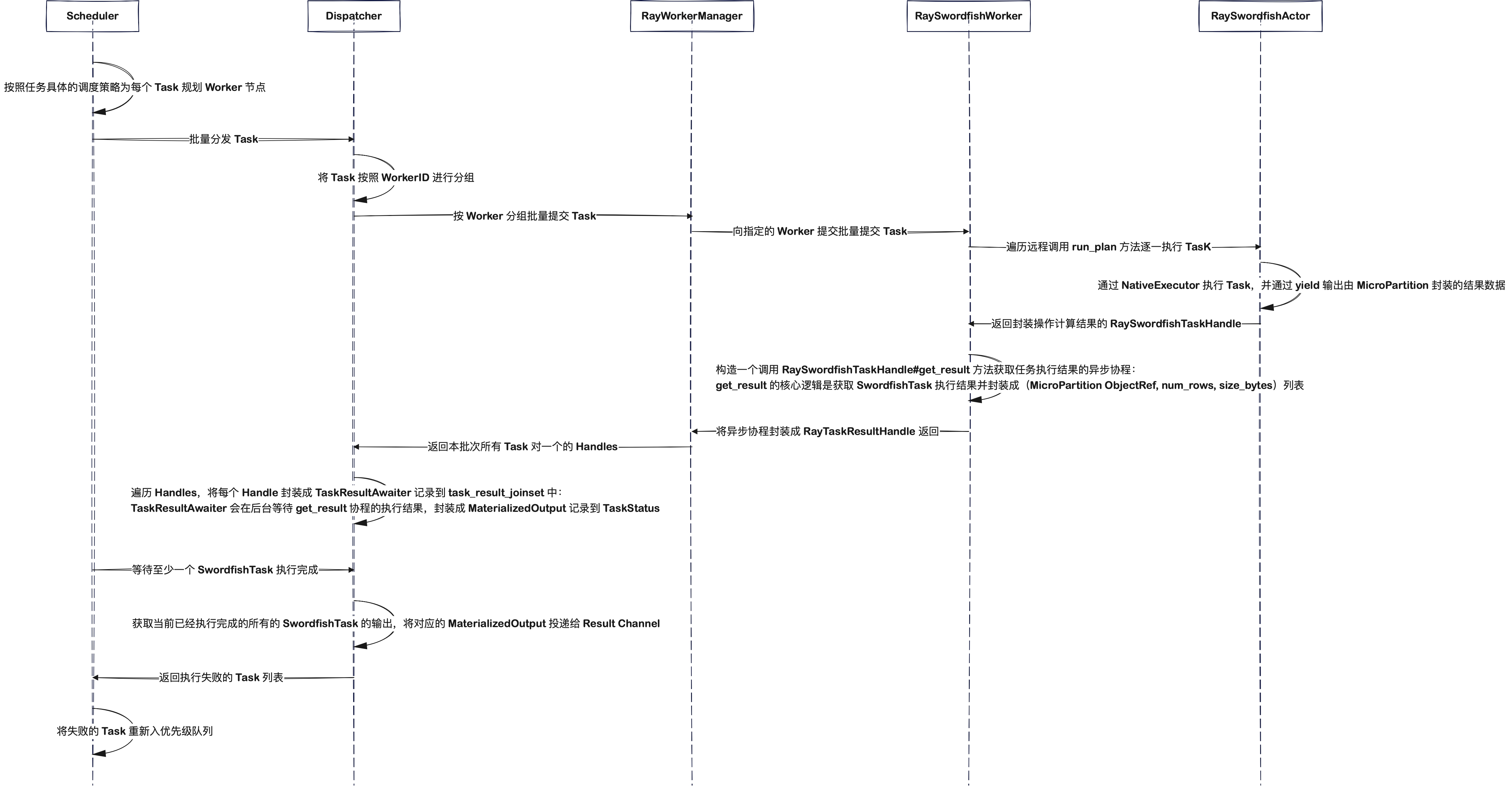
Flotilla 在内部定义了调度器 Scheduler 和分发器 Dispatcher 两个角色,前者负责调度由物理执行计划生成的一系列待执行的 SwordfishTask,按照调度策略规划每个 SwordfishTask 应该发送给哪个 Worker 节点;后者则负责将规划好的 SwordfishTask 按 Worker ID 分组,并批量分发给目标 Worker 节点执行。
对于每个用户提交的 Query,Flotilla 会为其创建并启动一个 Scheduler。Daft 默认提供了 DefaultScheduler 和 LinearScheduler 两类实现(默认使用 DefaultScheduler,可以通过 DAFT_SCHEDULER_LINEAR 环境变量启动 LinearScheduler), 二者的核心区别在于 DefaultScheduler 在资源允许的情况下会调度执行尽可能多的 SwordfishTask,而 LinearScheduler 则限制任何时刻只允许调度执行 1 个 SwordfishTask,从而保证串行执行的语义,适用于特定场景。 考虑大多数场景都会采用 DefaultScheduler,因此本小节我们主要以 DefaultScheduler 为例展开分析。
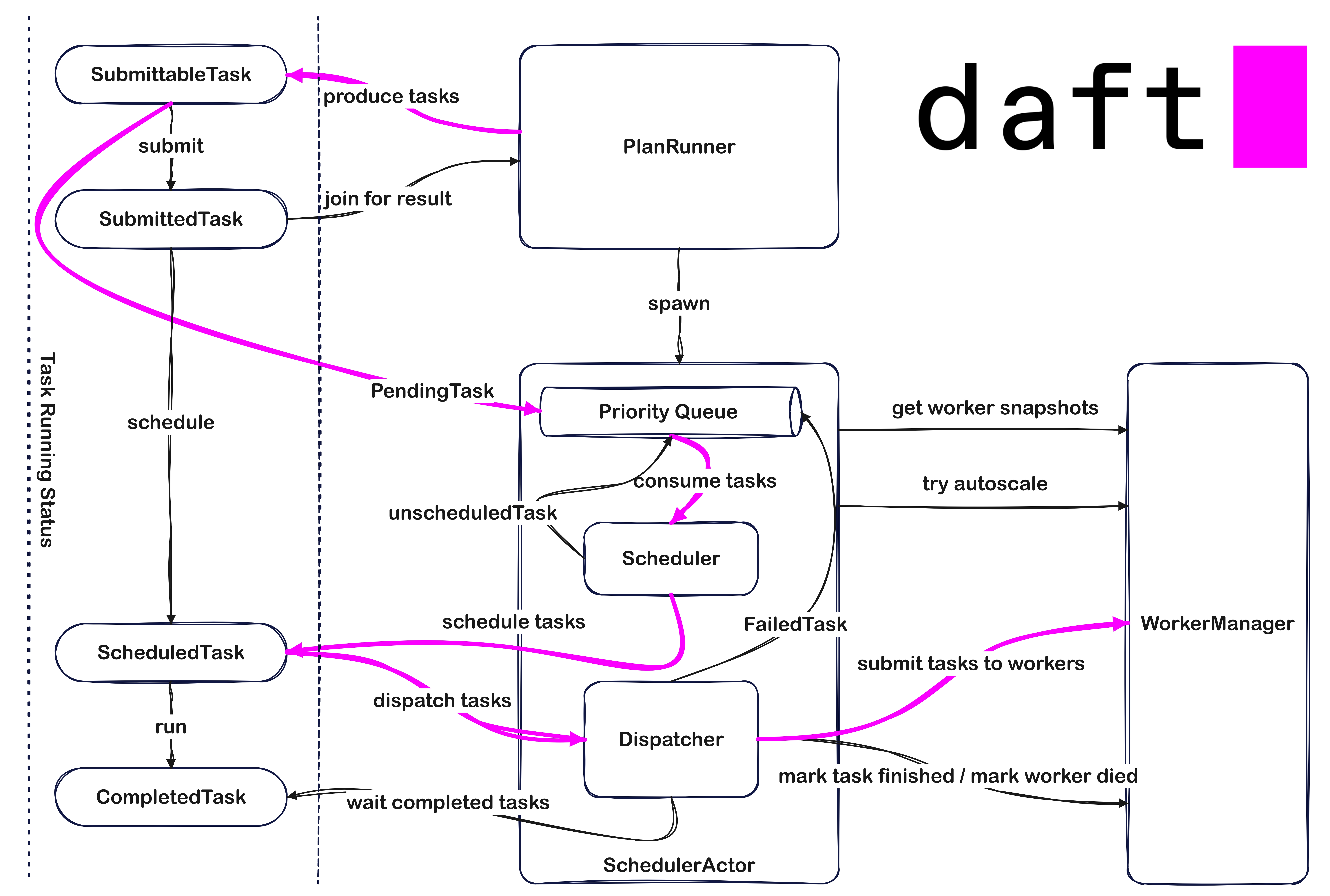
如上图所示,展示了 Flotilla 在调度分发 SwordfishTask 时相关组件的联动关系(其中红色线条表示任务调度分发的主线),核心执行流程可以概括为:
PlanRunner 在完成基于物理执行计划生成一系列 SwordfishTask 后,会逐一将这些 SwordfishTask 提交给 Scheduler 进行调度,并等待获取各个 SwordfishTask 的执行结果;
Scheduler 在内部会通过一个优先级队列来维护接收到可调度的 SwordfishTask 集合,并启动一个事件循环轮询消费该队列。对于可调度的 SwordfishTask 则尝试依据其调度策略分配 Worker 节点:
- 如果是 Spread 策略,则尝试从所有满足当前 SwordfishTask 资源需求的 Worker 节点中选择可用资源最多的 Worker 节点。
- 如果是 WorkerAffinity 策略,则尝试将其调度给当前 SwordfishTask 指定的节点。如果期望节点不能满足当前 SwordfishTask 的资源需求,则在允许的情况下会进一步尝试 Spread 调度策略,否则会将该 SwordfishTask 重新入队列,等待下一轮循环重试。
Dispatcher 会在 Scheduler 的事件循环中被触发执行向 Ray 集群批量分发已经规划好 Worker 节点的 SwordfishTask 集合。在实现层面,Dispatcher 会首先将 SwordfishTask 按照 Worker ID 进行分组,然后调用前面介绍的
WorkerManager#submit_tasks_to_workers方法向 Ray 集群的指定 Worker 节点批量提交 SwordfishTask。Scheduler 在每次事件循环中会等待至少 1 个 SwordfishTask 执行完成,并尝试输出当前所有已完成执行 SwordfishTask 的计算结果,针对执行失败的 SwordfishTask 会重新入队列,等待下一轮循环重试。
需要说明的一点是,对于整棵物理执行计划树而言,可能会被切分成多个 Stage,而 Flotilla 基于物理执行计划生成 SwordfishTask 的过程和调度分发 SwordfishTask 的过程在 Stage 之间,甚至是 Stage 内部是完全并行执行的,这样的好处是对于构造好的 SwordfishTask 可以立即被调度执行,从而保证 Pipeline 整体的数据流动性,提升执行效率。
聊聊分布式场景下 UDF 的运行机制
在大数据时代,用户通常习惯通过 SQL 开展数据分析任务,用户编写的 SQL 语句最终会被解析、转换成计算引擎的内置算子执行。然而,在如今 DATA + AI 的时代背景下,数据处理分析任务绕不开对于模型的调用,加上算法同学通常对 SQL 不够熟悉,因此“DataFrame + UDF”的应用组合逐渐成为主流,UDF 也由大数据时代的二等公民逐渐走到台前,扮演着与内置算子相当甚至更重要的角色。
Daft 支持多种类型的 UDF,包括 Lambda UDF、Batch UDF 以及 Class UDF,以满足用户不同的应用场景。在实际应用中,我们通常会使用 Class UDF 离线加载模型并实施推理,因此本小节我们简单介绍一下 Flotilla 是如何执行 Class UDF 的,关于 UDF 运行机制的深入解析,我们会在后续通过专门的文章进行介绍。
示例程序中我们实现了一个名为 ResNetModel 的 Class UDF,通过调用 ResNet50 模型实现对图片进行离线分类打标。前面在介绍 Flotilla 规划生成 SwordfishTask 时,曾提及过 Flotilla 会依据 UDF 的资源和并发度配置启动对应数量的 Ray UDFActor 以运行 Class UDF,并在启动期间执行对 Class UDF 的初始化逻辑。
Flotilla 在 SwordfishTask 中会为 Class UDF 添加一个 DistributedActorPoolProject 节点,我们可以将其理解为提交 UDF 任务的客户端,而将 UDFActor 理解为执行 UDF 任务的服务端。如上图所示,DistributedActorPoolProject 在本地会持有所有运行对应 UDF 的 UDFActor 实例引用,并将这些引用分为本地引用和远程引用两大类。当接收到待处理的请求时,DistributedActorPoolProject 会首先判断所在节点本地是否有可以调度的 UDFActor 实例,如果存在则轮询优先将请求发送给本地 UDFActor 实例进行处理,否则轮询请求远端 UDFActor 实例。
结语
本文,我们沿用之前的图片分类示例程序,从内部视角对 Daft 分布式执行引擎 Flotilla 的运行机制进行了剖析。Flotilla 作为 Daft 推出的全新分布式执行引擎,相对于 Legacy Ray Runner 而言,内置实现了对可执行任务的规划、调度和分发机制,通过巧妙的统筹运行在各个节点上的 Swordfish 单机执行引擎实现对于用户作业的分布式计算,并借助 Ray 实现了对于异构资源的灵活管理,从而为 Daft 实现对多模态数据实施更加高效的分布式处理提供了有力支撑。
Flotilla 作为一个分布式计算引擎,其背后设计和实现细节相当复杂,我们很难用一篇文章就能面面俱到。本文更多的还是梳理了 Flotilla 的执行主线,目标是引领你从整体层面去感知 Flotilla 引擎的内在设计和运行机制,以此作为你后续深入学习的引导。