通过图片分类任务探寻 Daft 运行机制之 Swordfish 引擎篇
Daft 是一款面向 DATA + AI 多模态数据处理与分析场景的计算引擎,支持单机和分布式两种运行模式,内核采用 Rust 语言编写,并提供 SQL 和 Python DataFrame 两种交互方式。
在文章《Processing 300K Images Without OOM: A Streaming Solution》中,作者介绍了基于 Daft 能够轻松实现对大规模图片数据集进行流式处理。那么,Daft 在幕后是如何执行用户输入的 SQL 或 DataFrame 的呢?在本文中,我们将继续以图片处理场景为切入点,通过一个典型的图片分类任务 DataFrame 示例,引领你深入探寻 Daft 单机执行引擎的运行机制。
本文英文版本已发布至 Daft 官网:“Exploring Daft’s Local Execution: The Swordfish Engine”
图片分类任务 DataFrame 示例
我们以 ImageNet 图片数据集为例构造一个包含图片 name、height、width,以及 url 四个属性的 Parquet 格式数据集,然后基于 Daft DataFrame 实现如下处理逻辑:
- 读取 Parquet 格式数据集,筛选出长宽为 256 像素的图片;
- 基于图片 URL 下载图片二进制数据,并将其解码成 Image 类型;
- 对图片执行简单的预处理操作,包括裁剪、归一化等;
- 调用 ResNet50 模型对图片执行离线分类打标,并返回相似性前 5 的分类标签;
- 将处理结果以 Lance 格式存储为新的图片数据集。
上述步骤对应的核心实现逻辑如下:
1 | df = (daft |
其中 transform 和 ResNetModel 为 UDF 实现,前者实现对图片数据的预处理操作,后者实现调用 ResNet50 模型对图片进行分类打标。
Daft 分层架构设计
在正式开始分析上述 DataFrame 示例的执行过程之前,我们首先从整体层面介绍一下 Daft 的分层架构设计。如下图所示,除了 Daft 执行所依托的本地或分布式 Runtime 环境之外,就 Daft 本身的整体架构设计而言,可划分为 API 层、Plan 层,以及执行层 3 个层次:
API 层: 提供 SQL 和 Python DataFrame 两种接入 API。Daft 通过对分布式多模态数据进行表格化抽象,并按照行维度切分成多个分片分散到集群的各个节点进行分布式处理,以实现对数据的并行计算。
Plan 层: 基于用户输入的 SQL 或 DataFrame 构建逻辑执行计划(LogicalPlan)和物理执行计划(PhysicalPlan)。虽然用户通过 SQL 或 DataFrame API 编写业务逻辑,但在 Daft 内部会将其转换成逻辑执行计划进行统一表示,并应用优化器对逻辑执行计划进行优化以获得更好的执行性能。经过优化处理后的逻辑执行计划将被进一步转换为物理执行计划,并应用物理执行计划层面的优化器做进一步优化。
执行层: 经过 Plan 层构造并优化得到的物理执行计划需要根据单机或分布式运行模式进一步拆分成一系列可被执行的 Task,并由调度器调度执行,同时管理 Task 的执行状态。
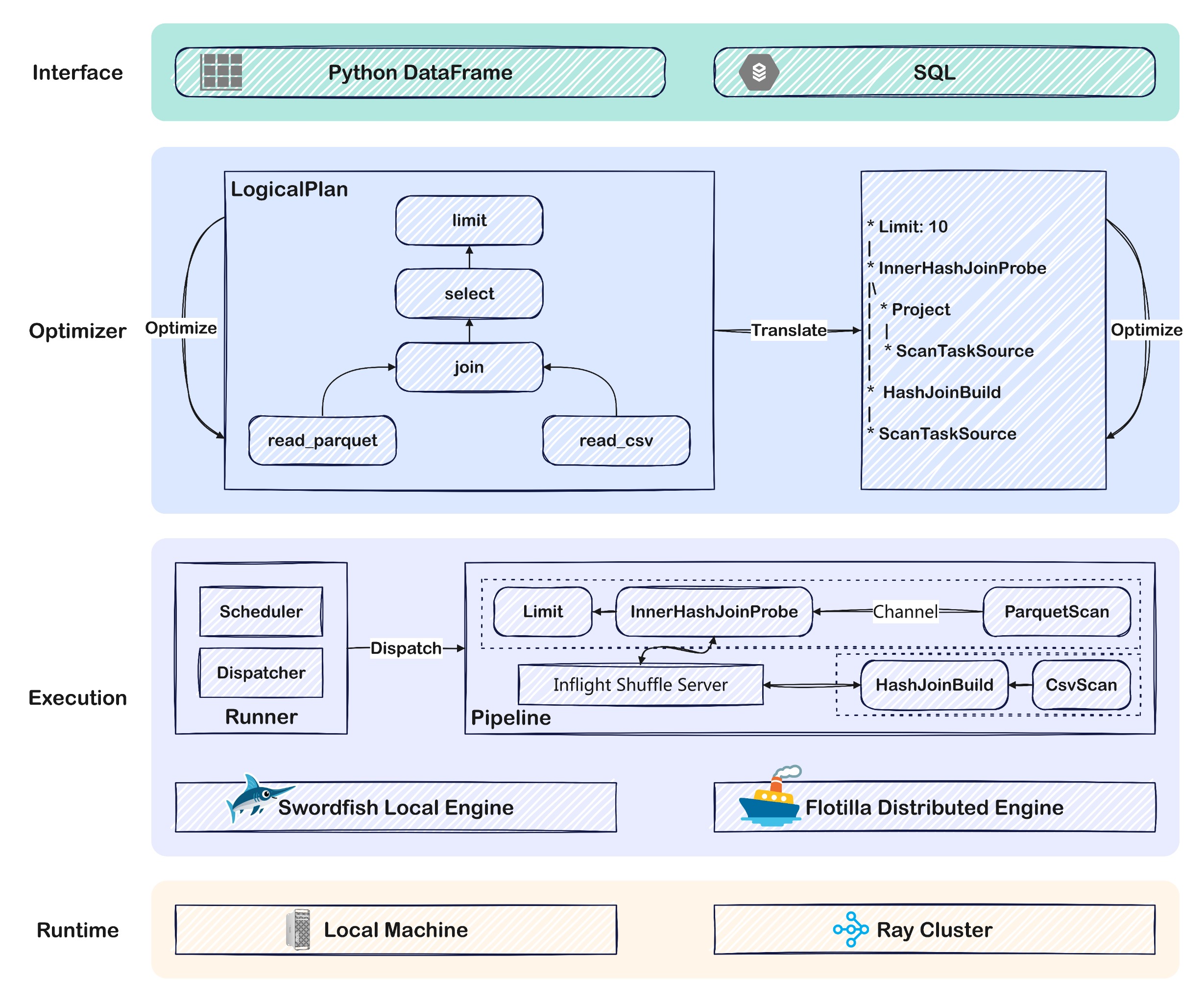
目前在 DATA + AI 领域主流的数据计算引擎(例如 Pandas、Polars)都默认仅提供单机执行引擎,其中 Polars 的分布式执行引擎仅在商业版提供,而 Dask 虽然可以看作是 Pandas 的分布式实现,但执行效率相对较低。Daft 在开源版本中同时提供了单机和分布式两套执行引擎,并允许在这两套引擎之间任意切换。
Daft 的单机执行引擎命名为 Swordfish,而分布式执行引擎命名为 Flotilla。相对 Flotilla 而言,Swordfish 的运行机制要简单许多,Flotilla 可以看做是分布式的 Swordfish 实现,理解 Swordfish 是进一步理解 Flotilla 的基础。 因此本文主要基于 Swordfish 引擎分析 Daft 如何执行用户输入的 DataFrame,后续我们将会通过专门的文章介绍 Flotilla 引擎的执行机制。
构造并优化逻辑执行计划
在对 Daft 整体架构有了初步感知后,我们正式切入正题。在图片分类任务示例中,用户定义的 DataFrame 应用程序会被 Daft 在内部表示成逻辑执行计划树。Daft 内部通过 LogicalPlanBuilder 基于用户构建的 DataFrame 构造逻辑执行计划树。例如,上述示例中的 DataFrame 程序对应的逻辑执行计划如下:
1 | * Limit: 100 |
说明:为保证可读性,本文中展示的执行计划会省略部分非关键内容。
虽然图片分类任务示例程序中没有使用 select 算子进行列筛选,但从上述逻辑执行计划可以看出包含多个 Project 节点,这是因为示例 DataFrame 中使用了多个 with_column 算子通过执行内置算子或 UDF 实现增加列。Daft 在内部使用 Project 节点承载 with_column 算子语义,对应的实现逻辑如下:
1 | pub fn with_columns(&self, columns: Vec<ExprRef>) -> DaftResult<Self> { |
我们在编写 DataFrame 时往往更加注重业务逻辑的实现和代码可读性,而 LogicalPlanBuilder 基于 DataFrame 构造逻辑执行计划的过程可以理解是一个“直译”的过程,所以上述逻辑执行计划在构成上与示例程序 DataFrame 在算子个数和构成上几乎一一对应。因此,直接将 LogicalPlanBuilder 构造的逻辑执行计划提交给执行引擎执行,通常执行效率非常低下。
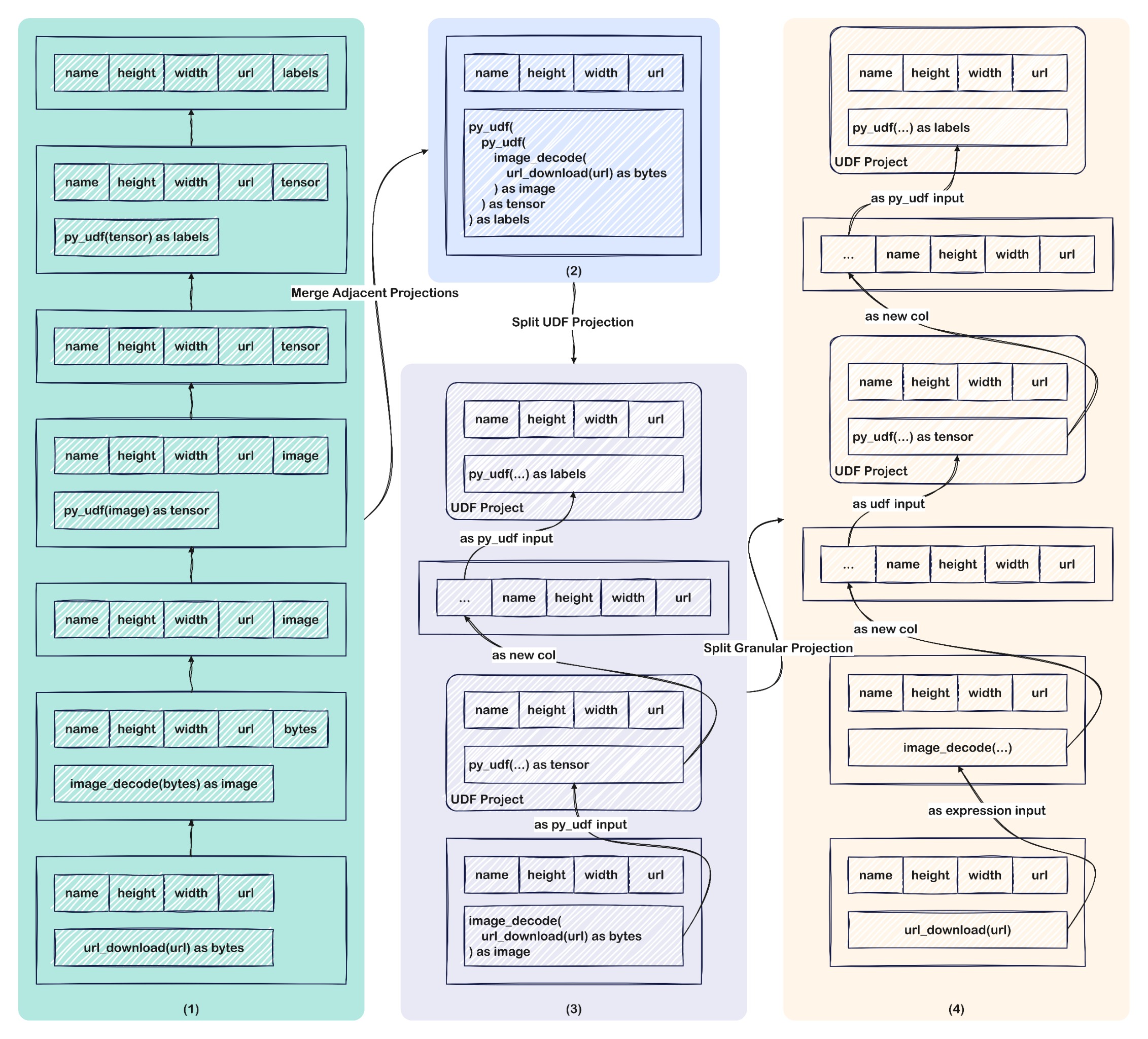
为了解决这一问题,Daft 与传统计算引擎一样,在内部实现了面向逻辑执行计划的优化器框架,并内置数十条优化规则实现对逻辑执行计划树进行优化改写。以图片分类任务 DataFrame 程序对应的逻辑执行计划为例,Daft 主要会应用如下优化规则对其进行优化:
Filter/Limit 表达式下推: 示例程序通过
filter算子筛选出长宽均为 256 的图片,并通过limit算子限制仅返回 100 条计算结果,优化器层面会将 Filter 和 Limit 表达式下推给 Scan 节点,实现过滤并减少需要扫描和处理的数据量。连续 Project 节点合并: 示例程序对应的逻辑执行计划树包含多个连续的 Project 节点,因此可以尝试将其合并以实现将多次 Project 投影操作合并为一次执行,这样在缩短执行链路的同时,也便于将 Project 表达式下推给 Scan 节点。如上图(1)所示,多个 Project 节点经过合并后可以压缩成为图(2)所示的 1 个 Project 节点。
UDF Project 分离: 经过合并后的 Project 可能会将 UDF 列与普通列合并在一起,这通常不便于框架实现 UDF 功能,同时在执行 UDF 时也不够灵活和高效,因此通常的做法是将 UDF Project 列从 Project 中分离出来进行单独处理。例如上述图(2)经过合并后的 Project 包含两个 UDF Project 列(即
py_udf列),其中内侧的 UDF 以解码得到的 image 列作为输入,其输出的 tensor 列继续作为外侧的 UDF 的输入,并输出 labels 列。因此我们需要将这两个 UDF Project 列从 Project 中分离,得到如图(3)所示的逻辑执行计划。细粒度 Project 节点拆分: 该优化规则目前主要面向包含
url_download表达式的 Project 节点。设想对于一个包含 1 万个 URL 的 CSV 文件,那么按照 Daft 的分区策略,这 1 万个 URL 将会集中到 1 个 Task 中进行处理,因此无法发挥分布式多节点并行下载的优势,同时也容易造成单节点 OOM 和连接数超限等问题。因此,我们可以将包含url_download表达式的 Project 节点分离出来单独处理,从而更加细粒度的控制批次大小和并发度。图(3)中包含url_download表达式的 Project 节点经过拆分后得到的逻辑执行计划如图(4)所示。物化 Scan 算子: 依据用户输入的数据源路径,Daft 会在优化逻辑执行计划期间访问数据源的元信息,并构造一系列 ScanTask 实现对数据的并发加载。同时,针对一些下推优化规则探测到的可以下推到 Scan 节点的表达式(例如 Filter、Limit、Project ),也会一并物化到 ScanTask 中。
示例 DataFrame 对应的逻辑执行计划在经过 Daft 优化器中的一系列优化规则优化改写后,进一步得到优化后的逻辑执行计划如下:
1 | * UDFProject: |
本小节仅对示例 DataFrame 命中的主要优化规则展开了介绍,实际上除上述几个优化规则外,Daft 优化器框架内置了大量的优化规则,典型包括消除 CrossJoin/Subquery/Repartition、谓词下推、列裁剪、Join Reorder 等,并且还在不断地演进和完善,旨在追求极致的计算性能。
构造并优化物理执行计划
经过优化器优化得到的逻辑执行计划本质上还是对用户构建的 DataFrame 在逻辑语义层面的表示,并不能直接被执行引擎执行。 逻辑执行计划层面更多关注的是用户提交的 SQL 或 DataFrame 需要“做什么”的问题,而无需关注需要在什么平台上执行,以及是单机执行还是分布式执行等“怎么做”的问题。 因此上述优化后的逻辑执行计划还需要进一步被转换成如下所示的物理执行计划:
1 | * UDF Executor: |
考虑 Daft 支持单机和分布式两套执行引擎,因此将逻辑执行计划转换成物理执行计划的过程需要区分是单机执行还是分布式执行。
本文主要介绍 Swordfish 单机执行引擎的运行机制。对于单机执行而言,转化成物理执行计划的过程可以简单理解为是对逻辑执行计划树进行深度优先遍历,并一一映射算子的过程,即将逻辑算子映射成为物理算子。当然,并不是所有的逻辑算子都有对应的物理算子实现,比如 Offset 这类逻辑算子会在优化器层面被改写成 Limit 算子,所以对于 .offset(x).limit(y) 这类操作最终在物理执行计划层面只需要一个 limit(y, x) 算子即可表达。
提交 Swordfish 单机执行
Daft 默认以单机模式执行用户输入的 SQL 或 DataFrame。Swordfish 作为 Daft 的单机执行引擎,采用 Pipeline 流式架构设计,并基于 Rust 语言实现,同时借助异步非阻塞 I/O 任务执行框架实现对数据的并行计算,具备优秀的执行性能和资源开销。
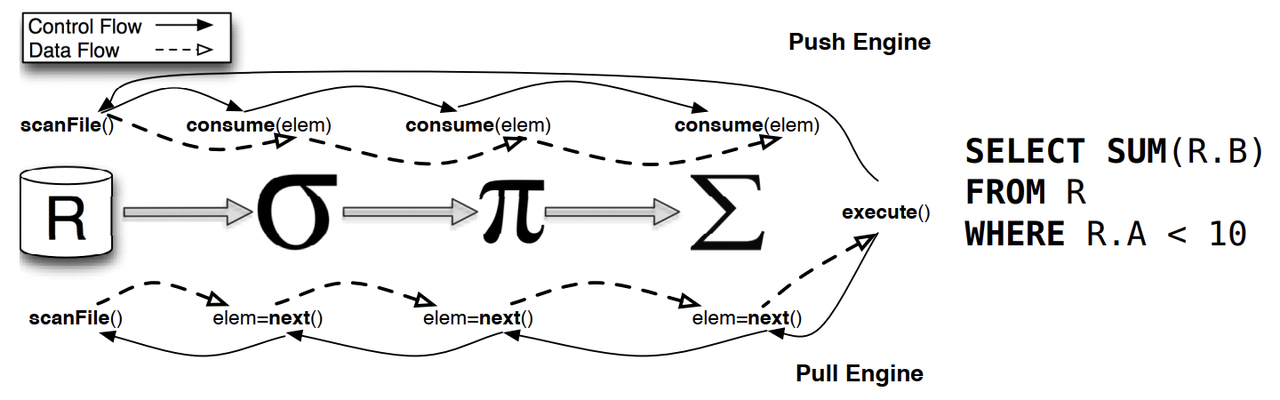
图片引用自论文 《Push versus pull-based loop fusion in query engines》
在实现层面,Swordfish 没有采用经典 Volcano 模型基于迭代器的 Pull 模式,而是采用基于数据块(Morsel)驱动的 Push 模式,本文我们不去谈论这两种模式孰优孰劣。在执行层面,当构成 Pipeline 管道的各个节点启动后,数据源节点即开始运行 Scan 任务加载数据,数据会被切分成一个个小的数据块,在节点之间采用“发布-订阅”模式通过 Channel 实现流式数据传递和处理。因此,整个 Pipeline 管道的运行可以看作是由数据块驱动,以一种 Push 的方式将数据块从 Source 节点推送给中间节点处理,并最终推送给 Sink 节点进行展示或写回文件系统。
构建 Pipeline 管道
对于示例 DataFrame 对应的物理执行计划,在提交给 Swordfish 执行引擎后,首先会将其转换成 Pipeline 管道。Swordfish 在内部定义了如下 4 类 Pipeline 节点:
| 节点类型 | 角色 | 并发数 | Operator 示例 |
|---|---|---|---|
| SourceNode | 数据源节点 | 依赖为数据分配的 Task 数,并依据经验值控制默认最大并发上限为 8 | PhysicalScan |
| IntermediateNode | 中间处理节点 | 取决于具体的 Operator 类型,默认为所在节点的 CPU 核数 | Project、Filter、UDF |
| BlockingSinkNode | 阻塞数据接收节点 | 取决于具体的 Operator 类型,默认为所在节点的 CPU 核数 | Aggregate、Repartition、WriteSink |
| StreamingSinkNode | 流式数据接收节点 | 取决于具体的 Operator 类型,默认为所在节点的 CPU 核数 | Limit、Concat、MonotonicallyIncreasingId |
Swordfish 执行引擎将物理执行计划转换成 Pipeline 管道的过程本质上也是一个对物理执行计划树进行深度优先遍历,并一一映射算子的过程,即将物理算子映射成为上述 4 类节点。示例 DataFrame 对应的物理执行计划经过转换后得到的 Pipeline 管道如下图所示:

构成 Pipeline 管道的各个节点通过类似消息队列的 Channel 进行连接,以“发布-订阅”模式实现数据的传递。
执行 Pipeline 管道
在执行阶段,Swordfish 首先会对 Pipeline 管道树进行深度优先遍历,并逐一调用各个节点的 start 方法启动运行各个节点。为了发挥多核 CPU 优势,Swordfish 引擎支持在节点内部、节点之间并发执行 Pipeline 任务,并允许用户控制节点并发度。Daft 在内部采用基于事件驱动的高性能异步 I/O 执行框架 Tokio 实现对于 Pipeline 各节点任务的并发调度执行。
例如对于上述图中的 Pipeline 管道,Swordfish 会按照从右至左的顺序逐一启动各 Pipeline 节点。当所有节点都启动后,整个 Pipeline 管道即处于运行状态。此时,Source 节点即开始运行 ScanTask 扫描数据,并将数据投递给与之绑定的 Channel,下游订阅该 Channel 的中间节点即可获得数据进行流式处理,并最终由 Sink 节点展示到终端或写回文件系统。整体执行流程如下图所示:

图片引用自《Processing 300K Images Without OOM: A Streaming Solution》,仅具象说明 Pipeline 中数据的流动方式,不代表示例 DataFrame 对于数据的处理过程。
下面我们继续以示例 DataFrame 对应的 Pipeline 管道为例,围绕以下 3 个问题进一步探究构成 Pipeline 管道的节点的执行机制:
- 数据是如何被加载的?
- 数据是如何被处理的?
- 数据是如何被写回的?
首先,我们来探究数据是如何被加载进 Pipeline 管道的。 前面已经介绍过,在构造和优化执行计划期间,Daft 会基于数据源路径构造和物化一系列的 ScanTask,用于实现对数据的并行加载。同时,Daft 在构建 Pipeline 管道期间会将数据源 Scan 算子封装到 SourceNode 节点中。在执行层面,Daft 在内部通过多生产者单消费者模式(MPSC: Multi Producer Single Consumer)实现对于这些 ScanTask 的调度执行。
具体来说,Daft 会在内部创建一个 MPSC 的 Channel ,所有的 ScanTask 在运行期间会依据数据源的具体格式调用对应的 SDK 流式加载数据,并将数据按照 Morsel 分片粒度投递给该 MPSC Channel,而下游的处理节点会订阅该 Channel,并从中以 Morsel 分片粒度消费数据并应用处理逻辑。当然,对于较大的数据源而言,Daft 可能会为其创建成千上万的 ScanTask,如果将这些 ScanTask 一并提交执行,势必会造成资源争抢,导致运行效率不高。因此,Daft 在内部会维护一个 Task 池子,以限制同一时刻能够执行的 ScanTask 数量上限。
其次,我们以执行 UDF 为切入点来探究数据在 Pipeline 管道中是如何被处理的。 不同于传统大数据处理场景,在多模态数据处理场景中,UDF 扮演着至关重要的作用,也是一个被高频使用的功能。如下所示,我们在示例 DataFrame 中定义了两个 UDF:
1 | .with_column('tensor', col('image').apply( |
其中 transform 是一个无状态的 UDF,用于按行实现对于图片数据的基础预处理操作;ResNetModel 是一个有状态的 UDF,该 UDF 会在初始化时加载 ResNet50 模型,并按批次调用模型对图片进行离线分类打标。
在实现层面,Daft 使用 IntermediateNode 节点将 UDF 封装到 Pipeline 管道中。作为 Pipeline 管道的中间节点,IntermediateNode 在启动后会执行:
- 按照 UDF 的
concurrency参数计算并设置能够同时执行 UDF 算子的 Worker 并发度,如果未设置则会沿用当前所在机器的 CPU 核心数; - 考虑 UDF 可能会设置
batch_size参数,因此需要将上游算子处理后的 Morsel 分片数据重新切分或合并,然后投递到与各 Worker 关联的 Channel 中; - 提交运行 UDF 的 Worker 集合,各 Worker 按照 MPSC 模式消费上游处理完成的数据,并执行 UDF 逻辑,同时将结果输出投递到输出 Channel 中,供下游节点继续消费处理。
对于 Swordfish 执行引擎而言,Daft 内部定义了 UdfOperator 用于执行 UDF 的内在业务逻辑。如果我们在定义 UDF 时配置了内存资源参数 memory_bytes,则引擎在开始执行 UDF 之前,会尝试从逻辑层面申请对应数量的内存资源。本文我们侧重于从整体流程层面了解 Swordfish 引擎的执行机制,关于 UdfOperator 如何执行 UDF 中定义的内在业务逻辑,将不在本文中继续展开。我们计划后续通过专门的文章介绍 Daft 关于 UDF 的执行机制。
最后,我们以写 Lance 格式数据为例来探究 Pipeline 管道中被处理完成的数据,是如何最终写回文件系统的。 Daft 内部定义了 LanceWriter 用于实现写 Lance 格式数据,而 LanceWriter 本质上是对 Lance Python SDK 的包装,内部定义了 write 方法实现按 Partition 分片将数据写成 Lance 格式。
针对 write_lance 这类 Sink 操作,Daft 使用 BlockingSinkNode 节点实现了 LanceWriter 与 Pipeline 管道的集成。在整体执行流程上,BlockingSinkNode 在启动后与 IntermediateNode 的执行流程类似,主要的区别在于:
- 在计算 Worker 并发度时,主要判断是否指定了
partition_by分区列,如果指定则默认采用当前所在机器的 CPU 核心数,否则就简单的设置为 1; - 每个 Worker 执行的不再是常规的数据处理逻辑,而是会首先创建 Writer 实例,然后基于该实例执行
Writer#write方法,通过调用对应格式的 SDK 将管道中的数据按照 Partition 分片粒度,以目标格式写回文件系统。
结语
在本文中,我们首先从宏观视角介绍了 Daft 的三层架构设计;然后借助一个图片分类任务 DataFrame 示例,从 API 层切入剖析了 Daft 在底层如何依据 DataFrame 构建并优化逻辑执行计划,以及如何将逻辑执行计划进一步优化改写成物理执行计划的过程;最后,我们以 Swordfish 引擎为依托,剖析了在单机运行模式下,Daft 依据物理执行计划构建 Pipeline 管道的具体方式,以及以 Pipeline 模式实现流式数据处理的执行过程。
限于篇幅,我们很难仅通过一篇文章将 Daft 内在原理分析的面面俱到,更多的还是引领你从整体执行层面感知 Daft 的内在实现,以此作为你深入学习 Daft 的引导。