Ack 机制是 Storm 能够保证消息至少被处理一次(at least once)的核心,从而保证消息不丢失。在 topology 有向无环图中,spout 向 bolt 发射消息,上游 bolt 也会向下游 bolt 发射消息。Storm 设置了一类 acker 类型的系统 bolt 组件用于接收所有组件发送的 ack 消息,监控数据在 topology 中的处理情况。如果处理成功则发送 __acker_ack 消息给 spout,否则发送 __acker_fail 消息给 spout,然后 spout 依据相应的消息类型采取一定的应对措施(例如消息重发等)。
Ack 算法利用了数学上的异或操作来实现对整个 tuple tree 的运行状况的判断。在一个由一条消息构成的 tuple tree 中,所有的消息都有一个 MessageId,本质上就是一个 map:
1
2
3
4
| public class MessageId {
private Map<Long, Long> _anchorsToIds;
}
|
字段 _anchorsToIds 存储的是 anchor 和 anchor value 的映射,其中 anchor 就是 rootId,它在 spout 中生成并且一路透传到 tuple tree 对应的所有下游 bolt 中,同一个 tuple tree 中的消息都具有相同的 rootId,用以唯一标识 spout 发出来的这条消息(以及从下游 bolt 根据这个 tuple 衍生发出的消息)。
算法介绍
示例引用自 官网,Ack 机制算法执行流程如下:
- spout 发送消息时生成 root_id。
- 同时对每一个目标 bolt task 生成
<root_id, random_long>(即为这个 root_id 对应一个随机 long 数值),然后随着消息本身发送到下游 bolt 中。假设有 2 个 bolt,生成的随机数对分别为:<root_id, r1> 和 <root_id, r2>。
- spout 向 acker 发送 ack_init 消息,它的 message_id 为
<root_id, r1 ^ r2>(即所有 task 产生的随机数列表的异或值)。
- bolt 收到 spout 或上游 bolt 发送过来的 tuple 之后,首先会向 acker 发送 ack 消息,message_id 即为收到的值。如果 bolt 下游还有 bolt,则与步骤 2 类似对每一个 bolt 生成随机数对(root_id 不变,但是值变为与当前值亦或新生成的随机数)。
- acker 收到消息后会对 root_id 下所有的值做异或操作,亦或结果为 0 则表示整个 tuple tree 被成功处理,否则就会一直等待直到超时,对应 tuple tree 处理失败。
- acker 向 spout 发送最终处理成功或失败的消息。

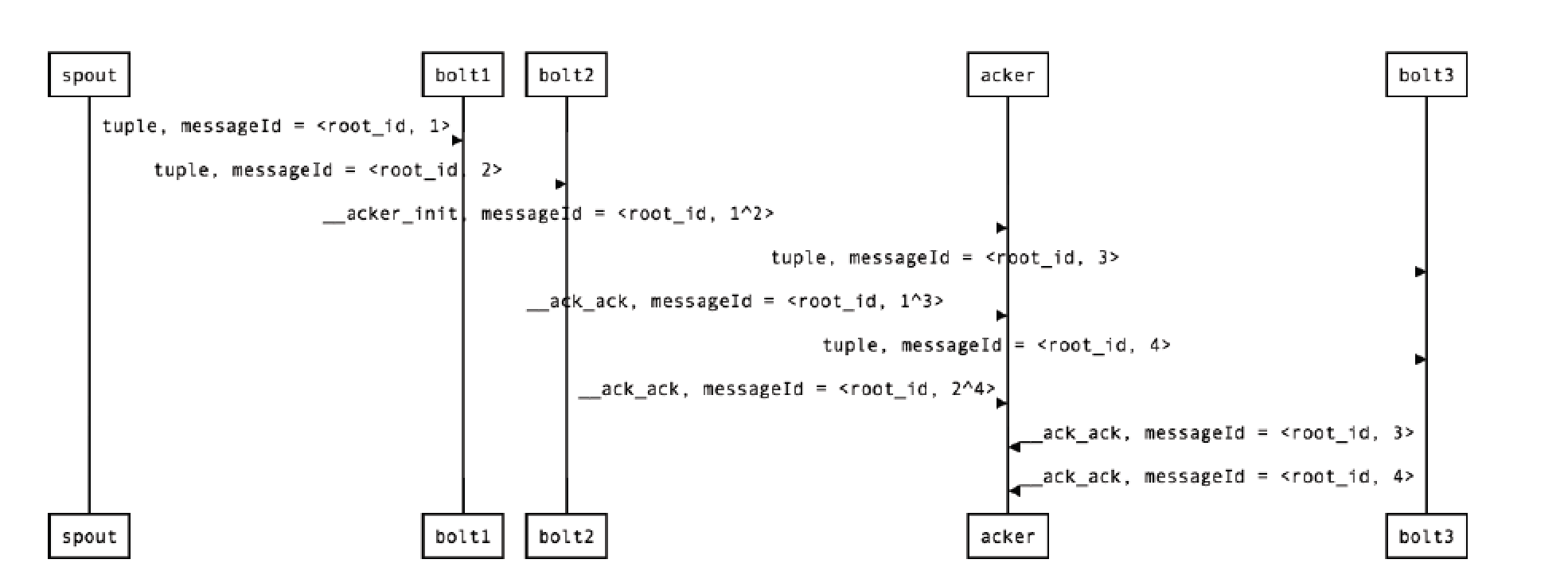
我们以一个稍微复杂一点的 topology 为例描述一下它的整个过程。假设 topology 结构为 spout -> bolt1/bolt2 -> bolt3,即 spout 同时向 bolt1 和 bolt2 发送消息,它们处理完后都向 bolt3 发送消息,bolt3 没有后续处理节点。对于这样一个 topology 而言,ack 机制的执行流程如下:
- spout 发射一条消息生成 root_id,由于这个值不变我们就用 root_id 来标识:
- spout -> bolt1 的 message_id =
<root_id, 1>
- spout -> bolt2 的 message_id =
<root_id, 2>
- spout -> acker 的 message_id =
<root_id, 1^2>
- bolt1 收到消息后生成如下消息:
- bolt1 -> bolt3 的 message_id =
<root_id, 3>
- bolt1 -> acker 的 message_id =
<root_id, 1^3>
- bolt2 收到消息后生成如下消息:
- bolt2 -> bolt3 的 message_id =
<root_id, 4>
- bolt2 -> acker 的 message_id =
<root_id, 2^4>
- bolt3 收到消息后生成如下消息:
- bolt3 -> acker 的 message_id =
<root_id, 3>
- bolt3 -> acker 的 message_id =
<root_id, 4>
- acker 总共收到以下消息:
1
2
3
4
5
| - <root_id, 1^2>
- <root_id, 1^3>
- <root_id, 2^4>
- <root_id, 3>
- <root_id, 4>
|
所有的值进行异或之后即为 1^2^1^3^2^4^3^4 = 0。
实现分析
下面从源码层面分析对于上面描述的算法的实现,相应逻辑分别位于 SpoutCollector、BoltCollector 和 Acker 中。先来看一下 spout 的逻辑,spout 在 emit 消息的时候顺带会向 acker 发送一条 ack_init 消息,相应实现位于 SpoutCollector#sendMsg 方法中,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| public List<Integer> sendMsg(
String out_stream_id, List<Object> values, Object message_id, Integer out_task_id, ICollectorCallback callback) {
final long startTime = emitTotalTimer.getTime();
try {
boolean needAck = (message_id != null) && (ackerNum > 0);
Long root_id = this.getRootId(message_id);
List<Integer> outTasks;
if (out_task_id != null) {
outTasks = sendTargets.get(out_task_id, out_stream_id, values, null, root_id);
} else {
outTasks = sendTargets.get(out_stream_id, values, null, root_id);
}
List<Long> ackSeq = new ArrayList<>();
for (Integer taskId : outTasks) {
MessageId msgId;
if (needAck) {
long as = MessageId.generateId(random);
msgId = MessageId.makeRootId(root_id, as);
ackSeq.add(as);
} else {
msgId = null;
}
TupleImplExt tuple = new TupleImplExt(topology_context, values, task_id, out_stream_id, msgId);
tuple.setTargetTaskId(taskId);
transfer_fn.transfer(tuple);
}
this.sendMsgToAck(out_stream_id, values, message_id, root_id, ackSeq, needAck);
if (callback != null) {
callback.execute(out_stream_id, outTasks, values);
}
return outTasks;
} finally {
emitTotalTimer.updateTime(startTime);
}
}
|
整个方法的执行步骤可以概括为:
- 为当前 tuple tree 生成在当前 spout 范围内唯一的 root_id;
- 获取下游目标 task 集合,并为每一个 task 生成对应的 message_id;
- 向所有下游目标 task 发送 tuple 消息;
- 向 acker 发送 ack_init 消息。
上面的步骤中 1 和 2 都是在做准备工作,步骤 3 则是发射 tuple 的主体流程,步骤 4 才是 spout 真正执行 ack 的过程。对于一个 tuple 而言,spout 会向所有下游目标 task 逐一发送该 tuple,同时在发射完成之后向 acker 发送一条 ack_init 消息。spout ack 的实现位于 SpoutCollector#sendMsgToAck 方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| protected void sendMsgToAck(
String outStreamId, List<Object> values, Object messageId, Long rootId, List<Long> ackSeq, boolean needAck) {
if (needAck) {
TupleInfo info = TupleInfo.buildTupleInfo(outStreamId, messageId, values, System.currentTimeMillis(), isCacheTuple);
pending.putHead(rootId, info);
List<Object> ackerTuple = JStormUtils.mk_list((Object) rootId, JStormUtils.bit_xor_vals(ackSeq), task_id);
this.unanchoredSend(topology_context, sendTargets, transfer_fn, Acker.ACKER_INIT_STREAM_ID, ackerTuple);
} else if (messageId != null) {
TupleInfo info = TupleInfo.buildTupleInfo(outStreamId, messageId, values, 0, isCacheTuple);
AckSpoutMsg ack = new AckSpoutMsg(rootId, spout, null, info, task_stats);
ack.run();
}
}
|
对于开启了 ack 机制的 topology 来说,方法会对所有下游目标 task 的 message_id 的随机数值执行亦或运算,将结果与 root_id 和当前 spout 的 task_id 一起封装成 tuple 发送给 acker。
下面再来看一下 bolt 的 ack 执行过程。bolt 将 emit 和 ack 分成两个方法,这主要也是为了方便开发者编程实现对于消息消费执行的控制。先来看一下 emit 过程,位于 BoltCollector#sendMsg 方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public List<Integer> sendMsg(String out_stream_id, List<Object> values,
Collection<Tuple> anchors, Integer out_task_id, ICollectorCallback callback) {
final long start = emitTimer.getTime();
List<Integer> outTasks = null;
try {
if (out_task_id != null) {
outTasks = sendTargets.get(out_task_id, out_stream_id, values, anchors, null);
} else {
outTasks = sendTargets.get(out_stream_id, values, anchors, null);
}
this.tryRotate();
for (Integer taskId : outTasks) {
MessageId msgId = this.getMessageId(anchors);
TupleImplExt tuple = new TupleImplExt(topologyContext, values, this.taskId, out_stream_id, msgId);
tuple.setTargetTaskId(taskId);
taskTransfer.transfer(tuple);
}
} catch (Exception e) {
LOG.error("bolt emit error:", e);
} finally {
}
return outTasks;
}
|
实际上一个 bolt 也可以看做是一个特殊的 spout,因为这个时候它相当于是当前 tuple tree 中一个 sub tuple tree 的消息起始点,所以在执行逻辑上与 spout emit 消息基本上相同。上面的方法实现整体与 SpoutCollector#sendMsg 也基本类似,这里我们主要看一下计算下游 task 的 message_id 的逻辑,位于 BoltCollector#getMessageId 方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| protected MessageId getMessageId(Collection<Tuple> anchors) {
MessageId ret = null;
if (anchors != null && ackerNum > 0) {
Map<Long, Long> anchors_to_ids = new HashMap<>();
for (Tuple tuple : anchors) {
if (tuple.getMessageId() != null) {
Long edge_id = MessageId.generateId(random);
put_xor(pendingAcks, tuple, edge_id);
MessageId messageId = tuple.getMessageId();
if (messageId != null) {
for (Long root_id : messageId.getAnchorsToIds().keySet()) {
put_xor(anchors_to_ids, root_id, edge_id);
}
}
}
}
ret = MessageId.makeId(anchors_to_ids);
}
return ret;
}
|
方法 getMessageId 的入参 anchors 是发送给当前 bolt 的 tuple,大部分时候只有一个,所以上面的方法实现我们可以简化一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| protected MessageId getMessageId(Tuple tuple) {
Map<Long, Long> anchors_to_ids = new HashMap<>();
if (tuple.getMessageId() != null) {
Long edge_id = MessageId.generateId(random);
put_xor(pendingAcks, tuple, edge_id);
MessageId messageId = tuple.getMessageId();
if (messageId != null) {
for (Long root_id : messageId.getAnchorsToIds().keySet()) {
put_xor(anchors_to_ids, root_id, edge_id);
}
}
}
return MessageId.makeId(anchors_to_ids);
}
|
简化之后应该更加清晰一些,实际上逻辑很简单,就是为下游 bolt 生成一个随机 long 数值作为 edge_id,然后将 edge_id 和 root_id 一起生成下游 bolt 的 message_id,也就是 <root_id, edge_id>。
下面我们再来看一下 bolt 的 ack 过程,位于 BoltCollector#ack 方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public void ack(Tuple input) {
if (input.getMessageId() != null) {
Long ack_val = 0L;
Object pend_val = pendingAcks.remove(input);
if (pend_val != null) {
ack_val = (Long) (pend_val);
}
for (Entry<Long, Long> entry : input.getMessageId().getAnchorsToIds().entrySet()) {
this.unanchoredSend(topologyContext, sendTargets, taskTransfer, Acker.ACKER_ACK_STREAM_ID,
JStormUtils.mk_list((Object) entry.getKey(), JStormUtils.bit_xor(entry.getValue(), ack_val)));
}
}
}
|
整个方法的逻辑就是拿到当前 task 的 edge_id 与目标 task 的 edge_id 进行亦或运算,然后将结果与 root_id(<root_id, egde_id1 ^ edge_id2>)一起发送给 acker。
最后我们来看一下 acker 的执行流程,acker 本质上也是一个 bolt,只不过是由系统创建,所以相应的处理逻辑位于 Acker#execute 方法中,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| public void execute(Tuple input) {
Object id = input.getValue(0);
AckObject curr = pending.get(id);
String stream_id = input.getSourceStreamId();
if (Acker.ACKER_INIT_STREAM_ID.equals(stream_id)) {
if (curr == null) {
curr = new AckObject();
curr.val = input.getLong(1);
curr.spout_task = input.getInteger(2);
pending.put(id, curr);
} else {
curr.update_ack(input.getValue(1));
curr.spout_task = input.getInteger(2);
}
}
else if (Acker.ACKER_ACK_STREAM_ID.equals(stream_id)) {
if (curr != null) {
curr.update_ack(input.getValue(1));
} else {
curr = new AckObject();
curr.val = input.getLong(1);
pending.put(id, curr);
}
}
else if (Acker.ACKER_FAIL_STREAM_ID.equals(stream_id)) {
if (curr == null) {
return;
}
curr.failed = true;
} else {
LOG.info("Unknown source stream, " + stream_id + " from task-" + input.getSourceTask());
return;
}
Integer task = curr.spout_task;
if (task != null) {
if (curr.val == 0) {
pending.remove(id);
List values = JStormUtils.mk_list(id);
collector.emitDirect(task, Acker.ACKER_ACK_STREAM_ID, values);
} else {
if (curr.failed) {
pending.remove(id);
List values = JStormUtils.mk_list(id);
collector.emitDirect(task, Acker.ACKER_FAIL_STREAM_ID, values);
}
}
}
collector.ack(input);
long now = System.currentTimeMillis();
if (now - lastRotate > rotateTime) {
lastRotate = now;
Map<Object, AckObject> tmp = pending.rotate();
if (tmp.size() > 0) {
LOG.warn("Acker's timeout item size:{}", tmp.size());
}
}
}
|
方法的实现虽然很长,但是逻辑还是比较清晰简单的,acker 会为每一个 spout task 创建一个 AckObject 对象,用于记录对应 tuple tree 的执行状态,并在每次接收到来自 spout 和 bolt 的 ack 消息时对该对象进行相应的更新,如果所有的亦或运算结果为 0 则表示 tuple tree 被执行成功,此时 acker 会向 spout 发送消息消费成功的消息,否则如果有 bolt 明确 ack fail,则向 spout 发送消息消费失败的消息,否则基于超时机制进行判定。
OK,关于 JStorm 的源码分析到这一篇基本上就结束了,我们分析了整个 JStorm 的运行骨架,知道我们编写的 topology 任务在集群上的执行过程,同时也了解了一个大规模分布式系统在实现上需要考虑的一些关键点,后面有时间会继续完善本系列,比如继续分析 trident 的实现机制等。