深入理解 JUC:ThreadPoolExecutor
线程池是 JUC 中的核心组件之一,在并发编程中我们一般都会引入线程池,一方面考虑是为了减少线程创建、销毁,以及频繁上下文切换所带来的性能开销,另一方面也是为了简化对线程创建、复用,以及消亡等过程的管理。ThreadPoolExecutor 是 JUC 线程池的核心实现,但在实际编码时我们可能很少直接使用该类,而是通过工具类 Executors 来创建线程池实例。
Executors 类提供了多种静态方法以简化线程池的创建,典型的应用场景如下:
1 | int nCpu = Runtime.getRuntime().availableProcessors(); |
上述示例中通过调用 Executors#newFixedThreadPool 方法,我们创建了一个大小为 CPU 核心数加 1 的线程池。此外,Executors 还定义了 Executors#newSingleThreadExecutor 和 Executors#newCachedThreadPool 方法分别创建固定大小为 1 和非固定大小的线程池。这些方法本质上都是对 ThreadPoolExecutor 类的封装,以简化线程池的使用,例如 Executors#newCachedThreadPool 方法的内部实现如下:
1 | public static ExecutorService newCachedThreadPool() { |
可以看到方法 Executors#newCachedThreadPool 封装了一个大小在 [0, Integer.MAX_VALUE] 之间,线程最大存活为时间为 60 秒的 ThreadPoolExecutor 实例,并以 SynchronousQueue 作为工作队列。
所以 ThreadPoolExecutor 可以视为 java 线程池的核心实现类,下面我们将一起来分析 ThreadPoolExecutor 的实现机制。
注意 :实际开发中一般不推荐使用 Executors 创建线程池,而应该通过 ThreadPoolExecutor 显式创建,这样能够让开发人员更加明确线程池的运行规则,规避资源耗尽的风险。Executors 返回的线程池对象主要存在以下弊端:
- FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为
Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 - CachedThreadPool:允许的创建线程数量为
Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
基础组件
在 ThreadPoolExecutor 类实现的开头有几个特殊的常量字段定义和相应的位运算(如下),而这正是整个线程池运行的基础支撑,理解这几个常量的含义是理解整个 ThreadPoolExecutor 实现的关键所在。
1 | // control,高 3 位表示线程池的运行状态 runState,低 29 位表示线程池内工作线程数 workerCount |
首先来看一下 ThreadPoolExecutor#ctl 常量,对应 AtomicInteger 类型。第一眼看到这个变量可能会一头雾水,但是随着对源码的深入阅读,逐渐能够理解其命名的灵感来源。作者应该是希望通过该变量来表达控制(control)的意思,因为整个线程池的运行状态和工作线程数量都通过该变量进行记录。这是一个 32 位的整型变量,其中 高 3 位用表示线程的运行状态(runState) ,而 低 29 位则用来记录当前工作线程的数量(workerCount) ,也就是说按照现有的能力,ThreadPoolExecutor 最多允许创建 229 - 1 个工作线程,约 5 亿多。这里我们将 workerCount 翻译为工作线程数量可能不太恰当,但是线程池会为每个 Worker 对象绑定一个线程(下文会进一步说明),所以 workerCount 理解为工作线程数量也不无道理。
1 | // 获取 ctl 中的 runState 值 |
类中定义了上述 3 个方法分别用来从 ThreadPoolExecutor#ctl 中获取线程池的运行状态 runState、工作线程数 workerCount,以及由 runState 和 workerCount 计算得到 ctl 值。ThreadPoolExecutor 中针对这 3 个变量的变量命名有个规律,一般 c 表示 ctl,rs 表示 runState,而 wc 则表示 workerCount,所以在阅读源码时如果遇到相应变量名,不妨联想一下,或许能够茅塞顿开。
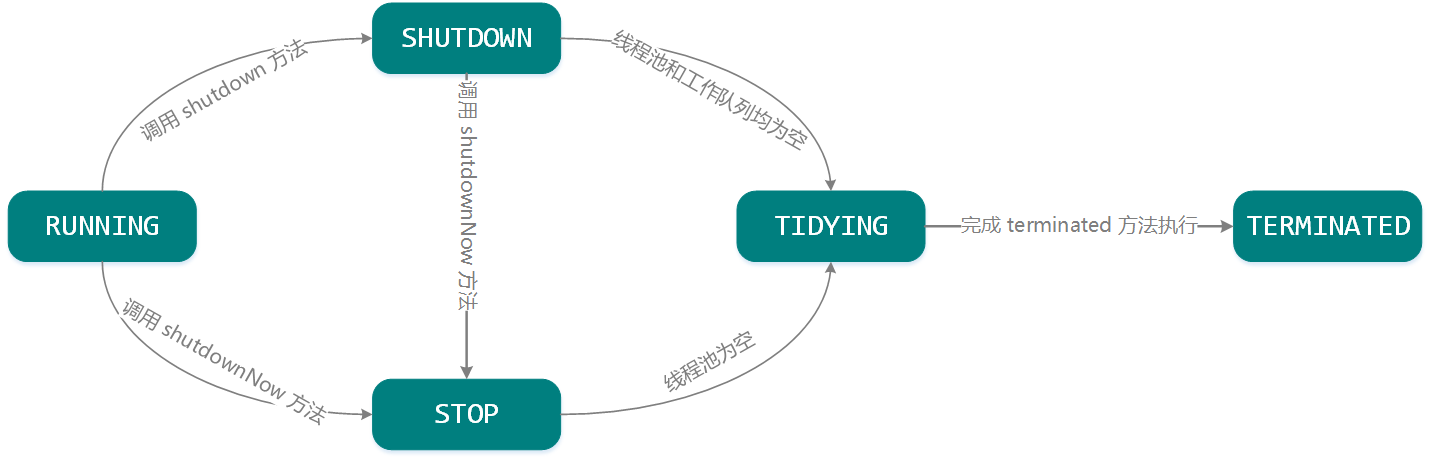
线程池定义了 5 种运行状态(状态转移关系如上图所示),即 RUNNING、SHUTDOWN、STOP、TIDYING,以及 TERMINATED,各状态的释义如下:
- RUNNING :该状态下线程池允许接收新的任务,并执行工作队列中的任务。
- SHUTDOWN :该状态下线程池不接受新的任务,但是会继续执行工作队列中的任务。
- STOP :该状态下线程池不接受新的任务,不执行工作队列中的任务,同时会中断正在运行中的任务。
- TIDYING :当所有的任务执行完,且工作线程数目为 0,线程池进入该状态后会调用
ThreadPoolExecutor#terminated方法。 - TERMINATED :当执行完
ThreadPoolExecutor#terminated方法后,线程池进入该状态。
线程池状态转换关系如下表:
| 前置状态 | 后置状态 | 转换条件 |
|---|---|---|
| RUNNING | SHUTDOWN | 显式调用了 shutdown 方法,或在线程池的 finalize 方法中调用了 shutdown 方法 |
| RUNNING or SHUTDOWN | STOP | 调用了线程池的 shutdownNow 方法 |
| SHUTDOWN | TIDYING | 当工作队列和线程池都为空的时候 |
| STOP | TIDYING | 当线程池为空的时候 |
| TIDYING | TERMINATED | 当方法 terminated 执行完毕的时候 |
ThreadPoolExecutor 利用 ThreadPoolExecutor#ctl 的高 3 位记录线程池的运行状态,并利用整型数值对每个状态进行标识,所以可以通过对整型数值的比较运算来判定当前的线程状态。ThreadPoolExecutor 提供了如下 3 个方法以对线程状态进行判定:
1 | private static boolean runStateLessThan(int c, int s) { |
各方法的作用可以通过方法名直观理解。
核心字段
ThreadPoolExecutor 中主要定义了如下基本字段,用于控制工作队列和线程池大小,以及线程池的运行,下面逐个解释说明。
1 | private final BlockingQueue<Runnable> workQueue; |
- workQueue :直译为工作队列,用于存放已提交待执行的任务,这是线程池需要具备的一个基础组件。ThreadPoolExecutor 采用阻塞队列 BlockingQueue 作为工作队列的类型,当队列已满时后续提交任务的操作将会被阻塞,当队列为空时,从队列中取任务执行的操作也将被阻塞。
- workers :工作线程集合,用于记录当前线程池中所有的工作线程,便于线程池对池中的线程数量、运行状态信息等进行管理。
- threadFactory :线程工厂,用于创建新的线程,默认采用 DefaultThreadFactory 实现类,当然我们也可以在创建线程池时自定义线程工厂。
- handler :用于指定饱和策略,我们往线程池中提交的任务不一定能够全部被线程池所接受,当线程池处于 SHUTDOWN 状态,或者线程池中的线程都处于运行状态但阻塞队列已满时,如果此时不能够再创建新的工作线程,则线程池可以基于饱和策略对任务提交操作进行反馈。JDK 为饱和策略定义了 RejectedExecutionHandler 接口,并提供了多种不同的策略实现,包括:AbortPolicy、CallerRunsPolicy、DiscardPolicy,以及 DiscardOldestPolicy 等,其中 AbortPolicy 是默认的饱和策略。
- keepAliveTime :线程池中的线程往往具备一定的生命周期,当一个线程长时间处于空闲状态时线程池可以将其灭亡,以减少系统资源占用。属性 keepAliveTime 定义了一个线程的最大生命周期,以微妙为单位(我们在创建线程池时可以指定最大生命周期的时间单位,但最终都将转换成微秒记录到 keepAliveTime 中)。一般来说线程池都会定义线程数量的下限,当线程数量减少到该下限值时,余下的线程将会一直存活,ThreadPoolExecutor 定义了 allowCoreThreadTimeOut 变量来控制这部分线程是否受 keepAliveTime 变量值所影响,该变量默认为 false,如果
allowCoreThreadTimeOut=true则任何线程到达生命周期时间时都会死亡。 - corePoolSize :核心线程数,可以理解为一个线程池所持有的最小线程数,默认当线程池空闲时这部分线程也会一直存活,不受 keepAliveTime 时间影响。在一开始提交任务且线程池中持有的线程数量还未达到该变量值时,线程池不会复用已有的空闲线程,而是会直接创建新的线程并执行任务。
- maximumPoolSize :最大线程数,用于控制线程池中线程数量上限,防止系统运行过程中创建大量的线程,从而浪费系统资源,频繁切换线程上下文。ThreadPoolExecutor 能够持有的线程数量不是无上限的,因为通过 int 类型记录线程池的工作状态,并且利用其中的低 29 位来记录线程数,所以一个线程池最多持有 229 - 1 个线程,该值记录在 CAPACITY 静态常量中,我们可以理解一个线程池的线程数量上限是
min(CAPACITY, maximumPoolSize)。需要注意的一点是, 当采用无界队列记录提交的任务时该变量将不起作用 ,具体原因在后面分析线程创建策略时再进行说明。
继续来看一下 ThreadPoolExecutor 的构造方法定义,ThreadPoolExecutor 提供了多种构造方法的重载版本,但都是对如下构造方法的各种定制:
1 | public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, |
方法中所有的参数已在上面进行了专门的说明,需要注意的一点就是参数中的 keepAliveTime 是有单位的,但最终还是将其转换成了微秒记录在 keepAliveTime 字段中。此外,构造方法还允许我们自定义工作队列的实现类型、线程工厂,以及饱和策略等。
任务调度
本小节来分析一下 ThreadPoolExecutor 的任务调度过程。下面的代码块展示了 ThreadPoolExecutor 的基本使用方式,通常我们会调用 ThreadPoolExecutor#submit 或 ThreadPoolExecutor#execute 方法往线程池提交任务。方法 submit 本质上还是对 execute 的封装,该方法的实现位于 AbstractExecutorService 类中,ThreadPoolExecutor 继承了该抽象类。对于我们提交的任务,线程池会基于当前线程池的负载决定是否执行饱和策略,如果我们提交的任务被线程池接受,那么何时调度执行该任务则完全由线程池来控制,这其中的运行原理(调度策略)就是接下来我们主要分析的对象。
1 | ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 8, 60L, TimeUnit.SECONDS, new SynchronousQueue<>()); |
AbstractExecutorService 为 AbstractExecutorService#submit 方法提供了多种重载版本,这里我们以 AbstractExecutorService#submit(Callable<T> task) 方法为例进行说明:
1 | public <T> Future<T> submit(Callable<T> task) { |
该方法首先通过 FutureTask 对 task 进行了封装,然后交给 ThreadPoolExecutor#execute 进行调度。方法 ThreadPoolExecutor#execute 的实现如下:
1 | public void execute(Runnable command) { |
上述方法所执行的逻辑可以分为 3 部分,每一部分都会调用 ThreadPoolExecutor#addWorker 方法,如下(注意调用参数设置):
- 线程池工作线程数小于 corePoolSize,则执行
addWorker(command, true)尝试新建工作线程执行提交的任务。 - 线程池工作线程数大于或等于 corePoolSize,且 workQueue 未满,则将提交的任务先记录到 workQueue 中。此时会再次检查工作线程数目,如果为 0 则执行
addWorker(null, false)新建工作线程。 - 线程池工作线程数大于或等于 corePoolSize,且 workQueue 已满,则执行
addWorker(command, false)尝试新建工作线程。
下面先对 ThreadPoolExecutor#addWorker 方法进行分析,理解了该方法的作用和实现细节,我们再回过头来看 ThreadPoolExecutor#execute 方法会显得比较直观。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
整个 ThreadPoolExecutor#addWorker 方法的执行逻辑可以分为两个步骤:
- 判断当前线程池是否允许创建新的线程,如果不能则直接返回 false;
- 如果允许则创建 Worker 对象,并启动与之绑定的线程。
首先来看 步骤 1 ,实现层面通过一个忙循环来执行判定的过程,第一次返回 false 的条件如下:
1 | if (rs >= SHUTDOWN && |
满足这一行语句的所有条件可以概括为:
- 当前线程池处于除 SHUTDOWN 以外的其它非运行态。
- 当前线程池处于 SHUTDOWN 状态,但是 firstTask 不为 null,即尝试提交新的任务。
- 当前线程池处于 SHUTDOWN 状态,但是工作队列为空,即之前累积的任务已被执行完成。
回忆一下我们在最开始总结线程池的运行态时,在哪些情况下线程池会继续执行我们提交的任务?实际上可以分为 RUNNING 和 SHUTDOWN 两类运行态,这两类运行态的含义分别如下:
- RUNNING:该状态下线程池接收新的任务,并执行工作队列中的任务。
- SHUTDOWN:该状态下线程池不接受新的任务,但是会继续执行工作队列中的任务。
如果当前线程池的状态是 RUNNING,那么这时候是可以接受新提交的任务的,并且可以执行工作队列中堆积的任务,此时是不满足这里列举的 3 种情况的。如果当前是 SHUTDOWN 状态,那么线程池不会再接受新的任务,但是会继续执行工作队列中堆积的任务。所以说如果这个时候我们有提交新任务,那么就满足条件 2,当然是不允许创建新的线程执行的。此外,如果这个时候我们工作队列已没有待执行的任务,即满足条件 3,那么线程池也不会再允许创建新的线程。
第二次返回 false 的条件如下:
1 | if (wc >= CAPACITY || |
这里的条件比较容易理解,如果当前线程池持有的线程数量已经达到理论上限 CAPACITY,当然不允许再创建新的线程,因为继续创建就溢出了。除了理论上限以外,线程池一般还存在实际容量上限,当达到该上限时同样不允许创建新的线程。这里的 core 参数是一个 boolean 类型,只有在当前工作线程数量小于 corePoolSize 时才为 true。对于线程池来说,如果当前工作线程数量小于 corePoolSize,则会直接创建新的工作线程去执行提交的任务,而不会将任务记录到工作队列中等待调度,所以在工作线程数量小于 corePoolSize 时是否创建新的线程应该以 corePoolSize 作为上限进行判断。因为过程中工作线程的数量是在变化的,如果走到这里说明工作线程的数量已经大于 corePoolSize,则不能直接创建新的线程,而是要先检查一下是否有空闲的工作线程可以复用。
再来看一下 步骤 2 ,这一部分涉及到 ThreadPoolExecutor 中定义的一个核心内部类 Worker:
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable { |
Worker 继承自 AbstractQueuedSynchronizer 抽象类,基于 AQS 实现了一个简单的不可重入独占锁,并复用 AQS 的 state 字段以表示锁的状态,其中 state=0 表示锁未被获取的状态,而 state=1 表示锁已经被获取的状态。初始时,state 值为 -1,以防止在运行 ThreadPoolExecutor#runWorker 方法之前被中断。
此外,Worker 类还实现了 Runnable 接口。当我们新建一个 Worker 对象时,线程池会为其绑定一个新的线程对象。当我们启动该线程时,实际上调用的是 Worker#run 方法,该方法实现如下:
1 | public void run() { |
方法 ThreadPoolExecutor#runWorker 描述了一个 Worker 不断执行任务的过程,任务可以是我们创建该 Worker 对象时绑定的,也可以是从工作队列中获取的。只要是存在待执行的任务,且当前线程池运行状态允许执行提交的任务,同时线程没有被中断,就可以循环的处理已提交的任务。当一个任务被执行完毕或因异常而退出,那么该任务会被标记为 null,从而防止任务被重复执行,同时可以让垃圾收集器回收任务对象,方法中在线程执行前后分别提供了模板方法方便扩展。
继续回到 ThreadPoolExecutor#addWorker 方法,当我们创建完 Worker 对象之后,线程并没有马上启动工作,而是会再次检测一下线程池的运行状态确保允许启动当前线程。如果允许则会记录当前 Worker 对象到 workers 全局集合中,该集合主要用来让线程池管理池中的线程对象,比如当前线程池的大小、检查各个线程的状态等等。如果一个 Worker 对象被成功注册,那么接下去就会启动与之绑定的线程对象,开始处理提交的任务。
介绍完了 ThreadPoolExecutor#addWorker 方法的作用和实现, 我们回过头来继续分析最开始的 ThreadPoolExecutor#execute 方法,有了对 Worker 对象的创建,以及任务调度过程的理解,再回过头来看该方法的运行逻辑会清晰许多。前面我们说了 ThreadPoolExecutor#execute 方法主要分为 3 个部分,更准确来说是 4 种场景,先简单概括一下:
- 如果线程池工作线程数小于 corePoolSize,则直接创建新的线程并执行提交的任务;
- 如果线程池工作线程数大于或等于 corePoolSize,且工作队列未满,则将提交的任务先缓存到工作队列中,此时会判断是否有工作线程,如果没有则会创建新的线程以继续调度执行缓存的任务;
- 如果线程池工作线程数大于或等于 corePoolSize,且工作队列已满,但是工作线程数还未达到线程池实际容量上限,则创建新的线程;
- 如果线程池工作线程数大于或等于 corePoolSize,且工作队列已满,同时工作线程数达到线程池实际容量上限,则触发饱和策略。
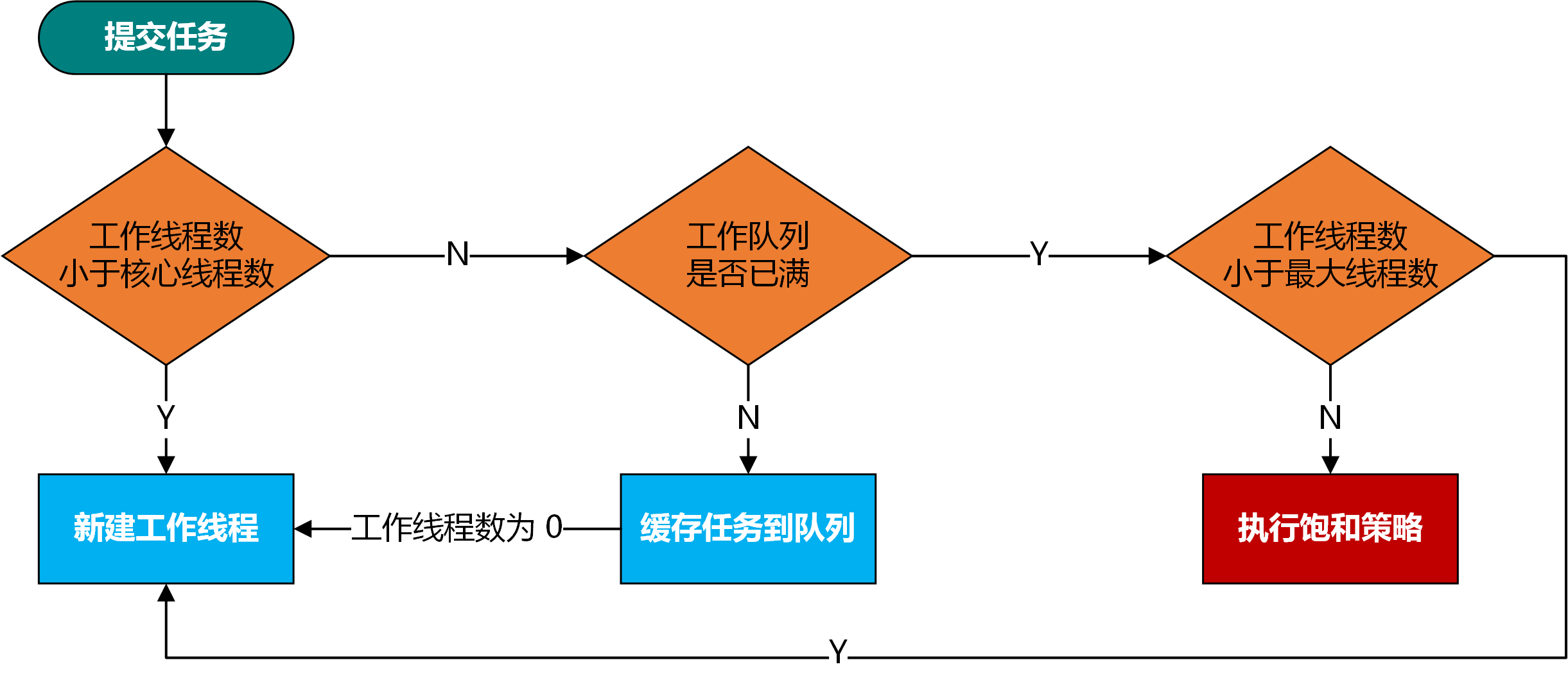
如上图描绘了线程池的任务调度执行流程。
先来看一下 步骤 1 ,这一步描述第 1 种场景(实现如下)。线程池判断当前工作线程数小于 corePoolSize,则执行 ThreadPoolExecutor#addWorker(command, true)。由于第 2 个参数为 true,所以会依据 corePoolSize 判断是否直接创建新的线程并执行提交的任务,因为这中间工作线程数量可能会发生变化,一旦工作线程数达到 corePoolSize,则需要执行其它的策略。
1 | // 1. 当前工作线程数小于 corePoolSize,正常情况下会新建一个线程,并将当前 command 绑定为该线程的第一个任务 |
再来看 步骤 2 ,这一步描述了第 2 种场景(实现如下)。能够执行到这里说明工作线程数量已经大于或等于 corePoolSize,同时线程池处于运行态。此时,会尝试先将提交的任务记录到工作队列中,如果过程中线程池的状态发生变更,切换为非运行态,则会从工作队列中移除刚刚提交的任务,并触发饱和策略;否则判断当前的工作线程数,如果为 0 则需要新建工作线程,因为工作队列中还有累积待执行的任务。
1 | // 2. 当前线程池处于运行态,且工作队列能够容纳当前任务 |
最后来看一下 步骤 3 ,这一步描述了第 3 和第 4 两种场景(实现如下)。能够运行到这一步需要满足两种情况之一:
- 当前线程池处于非运行状态;
- 工作队列已满。
如果线程池当前处于非运行状态,按照之前对于 ThreadPoolExecutor#addWorker 方法的分析可知,如果提交的任务不为 null,势必触发饱和策略。如果是因为工作队列已满的原因,则需要依据当前线程池是否还允许创建新的线程来决定是否触发饱和策略。
1 | // 3. 线程池处于非运行态,或工作队列已满 |
本小节的最后,我们来思考两个问题:
- 为什么当工作线程数达到核心线程数时,线程池选择将任务先缓存到队列,而不是继续创建线程以执行当前提交的任务呢?
- 如果希望改变线程池的调度策略,即当工作线程数达到核心线程数时继续创建线程执行提交的任务,只有当工作线程数达到上限时才选择将任务缓存到队列,应该如何实现呢?
首先来看 问题 1 ,ThreadPoolExecutor 采取的策略有点反直觉,直观的我们会认为线程池会在线程数达到上限时才会将后续的任务缓存到队列,那么为什么 ThreadPoolExecutor 要这么做呢?
应用程序广义上可以分为 CPU 密集型和 IO 密集型两大类。对于 CPU 密集型应用而言应该控制线程数尽量接近 CPU 核心数,以避免频繁切换线程上下文所带来的开销;对于 IO 密集型应用而言可以多创建一些线程,因为这一类应用大部分时间都在等待 IO 时间,CPU 相对较空闲。ThreadPoolExecutor 所采取的策略更加适用于 CPU 密集型应用,这应该也是考虑大部分的 java 应用程序都是 CPU 密集型。然而,对于 IO 密集型应用,如果直接使用 ThreadPoolExecutor 就显得有些呆滞,这也是像 Tomcat、Jetty,以及 Dubbo 一类应用需要自己实现线程池的动因。
再来看 问题 2 ,既然有应用场景,那么如何实现呢?
直观的思路就是将核心线程数与最大线程数设置相同,实现如下:
1 | ThreadPoolExecutor executor = new ThreadPoolExecutor( |
这是一种比较讨巧的做法,即所有的线程都是核心线程,虽然从表象上能够满足需求,但并不完全符合题意。
换一种思路,我们可以继承 ThreadPoolExecutor 类,重写 ThreadPoolExecutor#execute 方法,这也是面向对象编程比较直观的思路。不过,很可惜这条路走不通,因为 ThreadPoolExecutor 中一些状态属性的访问权限是 private,无法被继承。
既然无法通过继承访问 ThreadPoolExecutor 中的 private 状态属性,另外一种思路就是拷贝一份 ThreadPoolExecutor 类,然后修改 ThreadPoolExecutor#execute 方法。这条路确实能够走通,但是缺点也是显而易见的,因为自定义的 ThreadPoolExecutor 类只能在自己的应用程序内部使用,无法输出给其它第三方依赖库。
最后,我们来看看开源厂商的做法,这里以 Dubbo 为例。Dubbo 内部通过继承 ThreadPoolExecutor 实现了一个叫 EagerThreadPoolExecutor 的线程池类,其 解决思路的核心在于在工作队列的 offer 方法上做文章 。我们知道 ThreadPoolExecutor 在工作队列已满时会创建新的工作线程,而判断工作队列已满的方式就是调用工作队列的 offer 方法,如果该方法返回 false 则认为工作队列已满。
Dubbo 在实现层面继承 LinkedBlockingQueue 自定义实现了 TaskQueue 队列,其 TaskQueue#offer 方法实现如下:
1 | public boolean offer(Runnable runnable) { |
上述方法也诠释了 Dubbo 解决问题 2 的核心思想。关于 EagerThreadPoolExecutor 的实现这里不再展开,有兴趣的读者可继续阅读 Dubbo 源码。
饱和策略
上面我们多次提及到“饱和策略”一词,所谓饱和策略是指线程池无法容纳新任务的一种拒绝手段。JUC 定义了 RejectedExecutionHandler 接口用于描述饱和策略,当执行 ThreadPoolExecutor#reject 方法时,线程池会应用具体的饱和策略,如下:
1 | final void reject(Runnable command) { |
JUC 针对 RejectedExecutionHandler 接口定义了 4 个实现类,包括:AbortPolicy、DiscardPolicy、DiscardOldestPolicy,以及 CallerRunsPolicy。其中,AbortPolicy 是 ThreadPoolExecutor 的默认饱和策略。关于这 4 种饱和策略的释义如下:
- AbortPolicy :抛出 RejectedExecutionException 异常。
- DiscardPolicy :简单的丢弃当前提交的任务,而不抛出任何异常。
- DiscardOldestPolicy :从工作队列中移除等待时间最久的任务,并尝试提交当前任务。
- CallerRunsPolicy :尝试在调用线程中直接执行当前提交的任务。
上述策略执行当前提交的任务的前提是线程池处于运行态,否则仍然会静默忽略当前提交的任务。
总结
本文我们分析了线程池 ThreadPoolExecutor 设计与实现,总的说来线程池对于新任务的接受或拒绝,以及对于已接受任务的调度过程还是比较容易理解的。整个 ThreadPoolExecutor 的实现上,最令人敬佩的是 Doug Lea 大师在线程池状态和工作线程数量记录上的设计,以一个 int 型,通过位运算来实现所有的基础逻辑,简洁、高效,值得借鉴。
参考
- JDK 1.8 源码