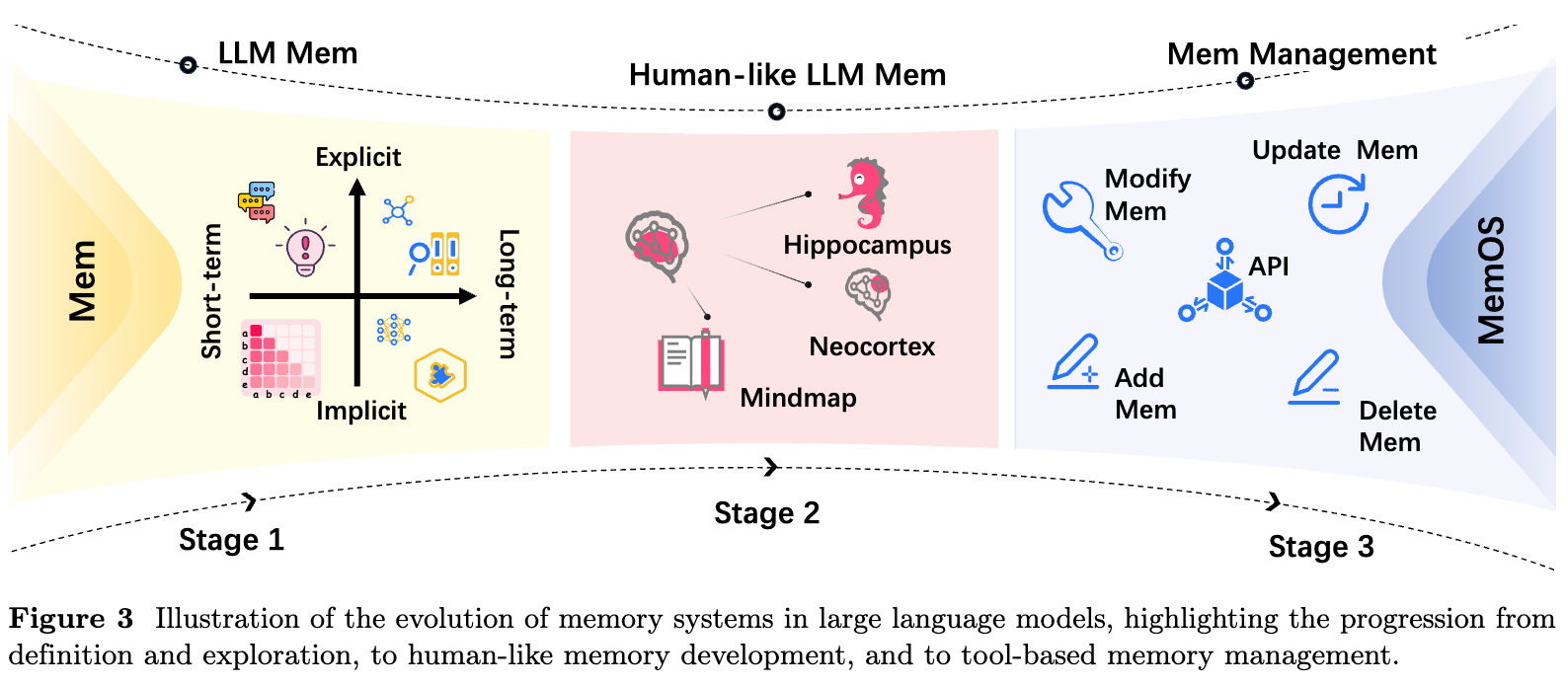
AI memory is not merely static storage, but a dynamic cognitive substrate critical for continuous learning and adaptation.
大语言模型(LLMs)已经展现出强大的理解、生成和推理能力,但它们默认仍更像一次性推理引擎:上下文窗口决定了“当前能看到什么”,模型参数承载的是训练阶段沉淀的通用知识,而跨会话、跨任务、跨环境的历史经验并不会自然沉淀下来。对 Agent 系统而言,这意味着它可以完成一次任务,却未必能记住用户偏好、复用过往轨迹、纠正旧信息,或在长期协作中持续成长。

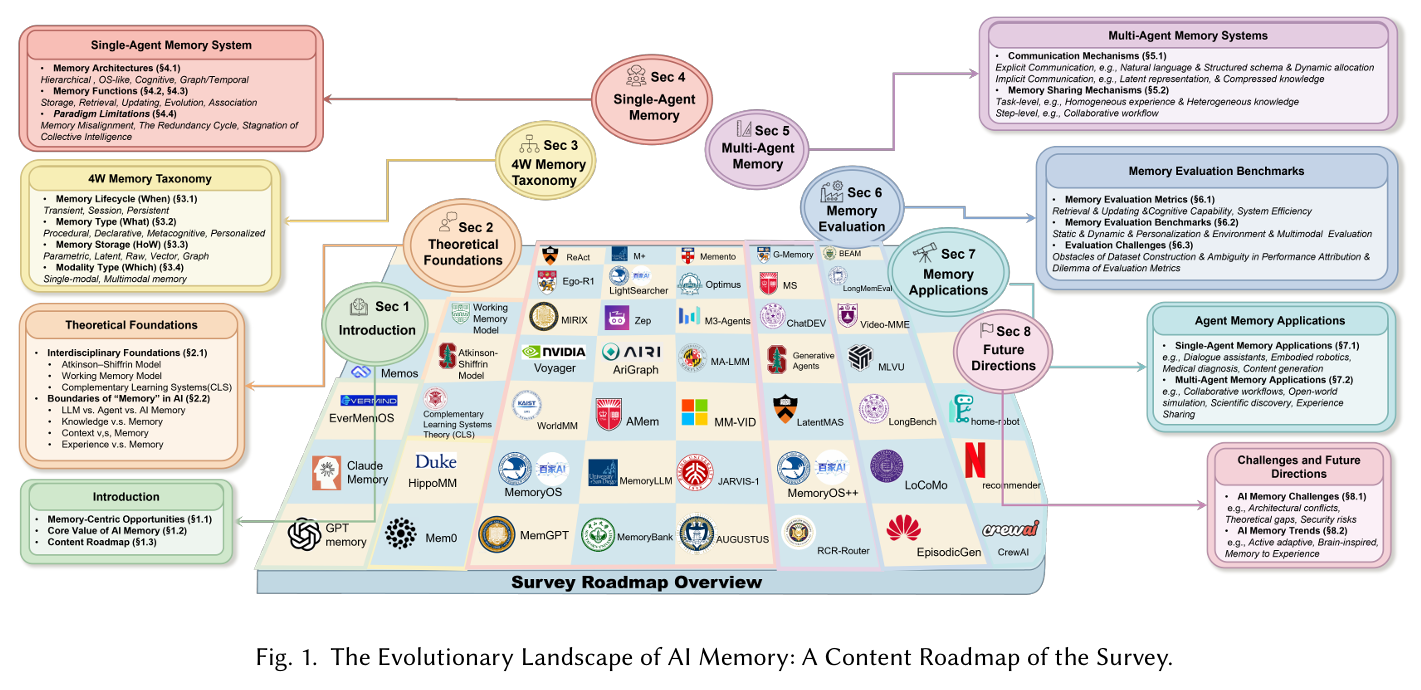
AI 记忆(AI Memory)试图补上这块能力拼图。本文基于综述文章《Survey on AI Memory: Theories, Taxonomies, Evaluations, and Emerging Trends》,围绕几个核心问题展开:首先区分 LLM Memory、Agent Memory 与 AI Memory 三个层次,并澄清 Memory 与 Knowledge、Context、Experience 的边界;随后介绍论文提出的 4W 分类法,从生命周期、内容类型、存储形式和模态维度理解记忆;接着讨论单 Agent 记忆系统的主流架构、基础流程与高阶能力,以及多 Agent 场景下的共享记忆、协作一致性和治理问题;最后整理记忆系统的评估维度与典型基准,说明如何判断一个 Agent 是否真正记得住、找得准、能更新、会遗忘、用得好。